Overview
이번 강의에서는 지금까지 배운 딥러닝 모델을 실제로 코드로 구현하는 방법에 대해 알아본다. 대표적인 딥러닝 프레임워크로는 PyTorch와 TensorFlow가 있다. 이러한 딥러닝 프레임워크를 사용하는 이유는 아래와 같다.
- 다양한 딥러닝 모델을 빠르게 프로토타이핑할 수 있다.
- Gradient를 자동으로 계산해 준다.
- GPU, TPU 등 다양한 기기에서 효율적으로 동작하도록 해 준다.
이 강의에서는 PyTorch에 대해 자세히 알아본다.
PyTorch

PyTorch는 아래 세 단계의 추상화 계층(Abstraction layer)으로 구성된다.
- Tensor: 가장 기본이 되는 계층으로, GPU에서 동작 가능한 다차원 배열
- Autograd: Tensor를 이용해 computational graph를 생성하고 자동으로 gradient를 계산
- Module: 다양한 computational graph를 모듈화하여 layer 단위로 쌓을 수 있는 최상위 계층
각 추상화 계층에서 간단한 2-layer fully-connected neural network를 구현해 보자.
Tensor
import torch
device = torch.device("cpu")
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in, device=device)
y = torch.randn(N, D_out, device=device)
w1 = torch.randn(D_in, H, device=device)
w2 = torch.randn(H, D_out, device=device)
learning_rate = 1e-6
for t in range(500):
h = x.mm(w1)
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
loss = (y_pred - y).pow(2).sum().item()
print(t, loss)
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2위 코드는 PyTorch의 Tensor만를 이용해 2-layer fully-connected neural network를 구현한 것이다. 우선 인풋 데이터인 x와 y를 생성하고, 랜덤한 weight w1, w2를 생성한다. 이때 N은 전체 데이터의 개수, D_in은 인풋 데이터의 dimension, H는 hidden layer의 dimension, D_out은 아웃풋 데이터의 dimension이다.
이후 for문 안에서는 먼저 forward pass를 수행한다. 이때 clamp 함수는 ReLU에 해당한다. 최종적으로 loss 변수에 값을 대입한 후에는 backpropagation을 수행한다. 직접 수식을 구현하고 중간 변수들을 대입하여 loss의 w1과 w2에 대한 gradient를 계산한다. 최종적으로 이 gradient를 이용하여 w1과 w2를 업데이트한다.
연산을 수행할 장치를 CPU에서 GPU로 바꾸고 싶으면 위 코드의 3번 줄을 아래와 같이 변경하면 된다.
device = torch.device("cuda")Autograd
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
w1 = torch.randn(D_in, H, requires_grad=True)
w2 = torch.randn(H, D_out, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
y_pred = x.mm(w1).clamp(min=0).mm(w2)
loss = (y_pred - y).pow(2).sum()
loss.backward()
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_()
w2.grad.zero_()위 코드는 PyTorch의 Autograd를 이용하여 같은 네트워크를 구현한 것이다. Tensor를 생성할 때 requires_grad=True를 설정하면 해당 Tensor를 이용해 연산을 할 때마다 computation graph를 자동으로 생성한다. gradient를 자동으로 계산해 준다. 따라서 학습 파라미터인 w1과 w2에 대해서만 requires_grad=True를 설정하였다.
Forward pass는 이전과 동일하게 직접 구현한다. 이때 requires_grad=True가 설정된 tensor가 연산에 포함되어 있으면 중간 변수를 PyTorch가 자동으로 관리해 주기 때문에 직접 지정할 필요가 없다. Backpropagation의 경우 훨씬 간단해지는데, 단순히 loss.backward()만 호출하면 loss tensor를 계산할 때 사용된 computational graph에 대해 자동으로 backpropagation을 수행한다.
계산된 gradient는 w1.grad, w2.grad를 이용해 접근할 수 있다. 또한 gradient를 사용한 후에는 zero_() 메소드를 사용하여 gradient를 0으로 초기화해 주어야 하는데, 그렇지 않으면 매 iteration마다 gradient가 계속해서 누적되기 때문이다. 또한 Optimization 과정은 computational graph에 포함되면 안 되기 때문에 torch.no_grad() 블럭 안에서 수행한다. Data augmentation 등 전처리 과정도 마찬가지로 torch.no_grad() 블럭 안에서 수행한다.
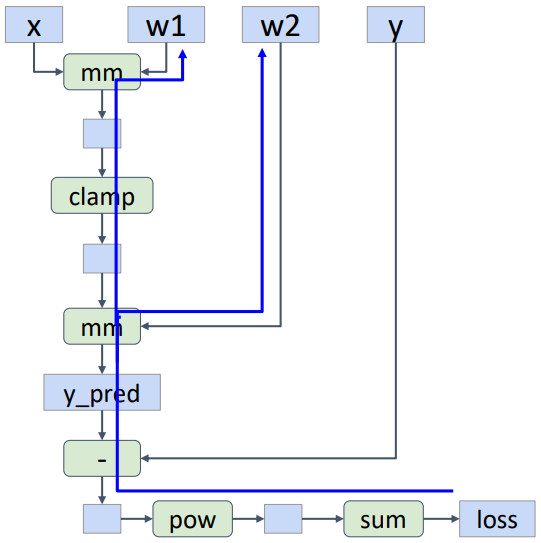
위 코드를 통해 생성된 computational graph는 위 그림과 같다. requires_grad=True가 설정된 w1과 w2에 대해서만 위 경로로 backpropagation을 진행하게 된다.
Defining New Operations
PyTorch에 기본으로 제공되지 않는 새로운 연산을 사용자가 직접 정의할 수 있다. 이때, 단순히 tensor를 입력받아 연산을 수행한 후 결과 tensor를 출력하는 함수를 구현할 수도 있고, 클래스를 이용해 직접 forwward pass와 backward pass를 연산을 구현할 수도 있다. Sigmoid 함수를 두 가지 방식으로 구현하면 아래와 같다.
def sigmoid(x):
return 1.0 / (1.0 + (-x).exp())이 방식은 단순히 위 전체 코드의 for문 안에서 연산을 직접 수행하는 것과 큰 차이가 없다. 따라서 computational graph도 각 기본 연산자에 대해 따로 node를 생성한다.
class Sigmoid(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
y = 1.0 / (1.0 + (-x).exp())
ctx.save_for_backward(y)
return y
@staticmethod
def backward(ctx, grad_y):
y, = ctx.saved_tensors
grad_x = grad_y * y * (1 - y)
return grad_x
def sigmoid(x):
return Sigmoid.apply(x)이 방식은 forward와 backward 메소드 자체를 직접 구현하는 방식이다. Sigmoid와 같이 backward pass를 직접 계산하여 구현할 수 있는 경우 이 방식을 사용할 수 있다. 이때 Sigmoid 클래스는 torch.autograd.Function을 상속받아야 하며, forward와 backward 메소드는 @staticmethod 데코레이터를 사용하여 정의한다. 또한 forward와 backward 메소드의 첫 번째 인자는 ctx로, 이를 이용해 forward pass에서 생성된 중간 변수를 저장하고 backward pass에서 사용할 수 있다. 마지막으로 Sigmoid.apply(x)를 수행하는 함수를 따로 정의하여 Sigmoid 클래스를 기존 코드에 적용할 수 있다.
대부분의 연산은 단순히 함수로만 구현하고, forward pass나 backward pass에 대해 특별히 다른 연산을 지정해 주어야 하거나 CPU, GPU 등 커널별로 다른 연산을 지정하고 싶을 때에만 클래스 방식을 사용한다.
Module
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out))
learning_rate = 1e-6
for t in range(500):
y_pred = model(x)
loss = torch.nn.functional.mse_loss(y_pred, y)
loss.backward()
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
model.zero_grad()Module 계층의 경우 사전에 연산이 정의된 layer들을 쌓아 더 크고 깊은 네트워크를 구축할 수 있다. 이때 torch.nn 패키지를 이용한다. 이 방식을 사용하는 경우, 학습 파라미터 변수를 직접 선언할 필요 없이 인풋과 아웃풋 변수만 정의하면 된다. 또한 Sequential을 이용해 각 layer를 순서대로 배치할 수 있는데, 이때 사전에 정의된 layer들을 불러와 반복 사용할 수 있기 때문에 코드가 훨씬 간결해진다. 각 layer들을 불러올 때 weight matrix나 bias vector 등 필요한 학습 파라미터도 함께 생성된다. 위 코드의 경우 FC layer, ReLU, FC layer를 순서대로 쌓은 네트워크를 구현한 것이다.
이후 forward pass는 model(x)로 간단히 수행할 수 있고, loss 함수는 torch.nn.functional 패키지에서 mse_loss를 불러와 간단히 계산할 수 있다. Backward pass의 경우 loss.backward()를 호출하면 되는데, 중간 변수가 layer와 함께 생성되며 requires_grad=True인 상태로 생성되기 때문에 모든 학습 파라미터에 대해 gradient를 자동으로 계산할 수 있다.
마지막으로, gradient descent를 수행할 때에는 model.parameters()를 이용해 모든 학습 파라미터에 대해 접근할 수 있다. Update를 마친 후에는 model.zero_grad()를 호출하여 모든 gradient를 한번에 0으로 초기화해 준다.
Weight initialization 또한 마찬가지로 간단히 설정할 수 있는데, 위 코드에서 다루지는 않는다.
Using Optimizers
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out))
learning_rate = 1e-6
optimizer = torch.optim.Adam(model.parameters(),
lr=learning_rate)
for t in range(500):
y_pred = model(x)
loss = torch.nn.functional.mse_loss(y_pred, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()위 코드는 앞서 살펴본 module 계층의 코드와 동일한데, torch.optim 패키지를 이용해 Adam optimizer를 사용한 것이다. 생성자에 model.parameters()를 입력함으로써 모든 학습 파라미터에 대해 optimization을 수행할 수 있다. optimizer.step()을 통해 모든 학습 파라미터에 대해 gradient descent를 수행하며, optimizer.zero_grad()를 호출하여 모든 gradient를 한번에 0으로 초기화해 준다.
Optimizer를 사용하는 경우, learning rate, weight decay, momentum 등 다양한 hyperparameter를 설정할 수 있으며, 다양한 optimizer를 사용할 수 있다. 또한, learning rate scheduler를 사용하여 학습 도중에 learning rate를 조절할 수도 있다.
Defining New Modules
import torch
class TwoLayerNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(TwoLayerNet, self).__init__()
self.linear1 = torch.nn.Linear(D_in, H)
self.linear2 = torch.nn.Linear(H, D_out)
def forward(self, x):
h_relu = self.linear1(x).clamp(min=0)
y_pred = self.linear2(h_relu)
return y_pred
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = TwoLayerNet(D_in, H, D_out)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
for t in range(500):
y_pred = model(x)
loss = torch.nn.functional.mse_loss(y_pred, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()기존에 nn 패키지에 구현된 conv layer, pooling layer 등을 이용할 수도 있지만, 이러한 기본 layer들을 조합하여 직접 원하는 모듈 단위를 설계하는 경우도 많다. 이때는 torch.nn.Module을 상속받아 새로운 모듈 클래스를 구현하면 된다.
클래스에서는 생성자와 forward pass를 정의한다. 우선 생성자에서는 상속받은 클래스의 생성자를 호출하고 각 layer를 정의한다. 그리고 forward pass에서는 정의한 layer들을 이용해 네트워크를 직접 구성한다. 이후 해당 클래스를 호출함으로써 모델을 생성하고, 이후에는 앞서 살펴본 방식과 동일하다.
이러한 방식을 통해 PyTorch에 구현되어 있지 않은 residual block과 같은 모듈을 만들고, 이를 재사용하여 더 깊은 네트워크를 구축할 수 있다.
class ParallelBlock(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(TwoLayerNet, self).__init__()
self.linear1 = torch.nn.Linear(D_in, D_out)
self.linear2 = torch.nn.Linear(D_in, D_out)
def forward(self, x):
h1 = self.linear1(x)
h2 = self.linear2(x)
return (h1 * h2).clamp(min=0)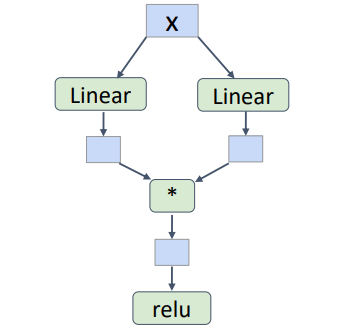
클래스의 정의를 바꾸어 위와 같은 구조도 만들 수 있다.
model = torch.nn.Sequential(
ParallelBlock(D_in, H),
ParallelBlock(H, H),
torch.nn.Linear(H, D_out))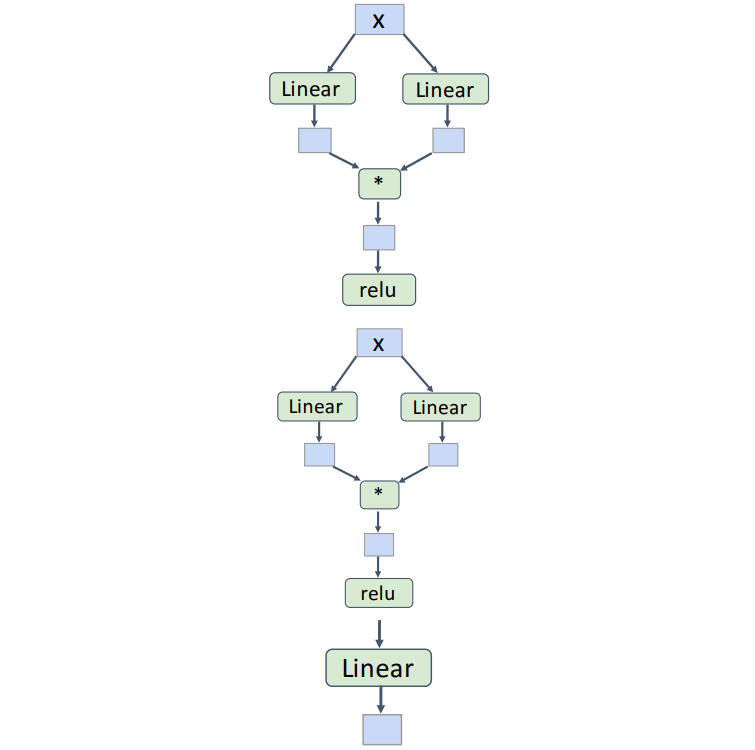
또한 이 ParallelBlock을 Sequential을 이용해 여러 층으로 쌓을 수 있다. 이러한 방식을 통해 효율적으로 네트워크를 확장할 수 있다.
DataLoader
import torch
from torch.utils.data import TensorDataset, DataLoader
N, D_in, H, D_out = 64, 1000, 100, 10, True, None
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
loader = DataLoader(TensorDataset(x, y), batch_size=8)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
for epoch in range(20):
for x_batch, y_batch in loader:
y_pred = model(x_batch)
loss = torch.nn.functional.mse_loss(y_pred, y_batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()PyTorch는 또한 데이터를 불러오고 iterate하는 모듈을 제공한다. Dataset 객체는 데이터를 모아 둔 것이고, DataLoader 객체는 Dataset 객체에 든 데이터를 이용하여 minibatching, shuffling, multithreading, data augmentation 등을 수행한다. DataLoader에서 데이터를 불러올 때도 위 코드와 같이 간단하게 사용할 수 있다.
새로운 데이터셋을 사용할 때는 Dataset 객체를 이용하는데, 데이터를 어떻게 읽을 것인지를 설정할 수 있다.
Pretrained Models
import torch
import torchvision
alexnet = torchvision.models.alexnet(pretrained=True)
vgg16 = torchvision.models.vgg16(pretrained=True)
resnet101 = torchvision.models.resnet101(pretrained=True)torchvision 패키지는 다양한 pretrained model을 제공한다. 이러한 pretrained model을 불러오면 이미 학습된 weight를 바로 사용할 수 있어서 편리하다.
Dynamic Computation Graphs
PyTorch의 중요한 특징 중 하나는 dynamic computation graph 방식을 사용한다는 것이다. 이는 매 iteration마다 computational graph를 새로 생성하는 것을 의미한다. 반대 개념인 static computation graph는 처음에 computational graph를 정의하고, 이후에는 그 그래프를 그대로 사용하는 방식이다.
Dynamic computation graph 방식은 코드 내에서 그래프 생성을 간단하게 제어할 수 있어 효과적이다. 예를 들어 매 iteration마다 특정 조건에 따라 다른 연산을 수행해야 하거나 네트워크의 구조를 바꾸어야 하는 경우, static computation graph를 사용하면 그 조건문 자체를 그래프에 반영해야 하기 때문에 오히려 그래프가 복잡해진다. 하지만 dynamic computation graph 방식을 사용하면 forward pass 과정을 통해 그래프 생성을 간단하게 제어할 수 있다. 따라서 RNN 등 loop를 이용한 네트워크를 설계할 때 효율적이다. 또한 dynamic computation graph 방식은 디버깅이 용이하다는 장점도 있다.
Static computation graph 방식의 장점은 사람이 만든 graph를 한 번 최적화할 수 있다는 것과 deploy 시에 유리하다는 것이다. Python으로 그래프를 정의하고 학습시킨 뒤 C++로 변환하여 배포할 수도 있다.
PyTorch에서는 JIT(Just In Time Compiler)를 통해 static computation graph를 사용할 수도 있다.
TensorBoard
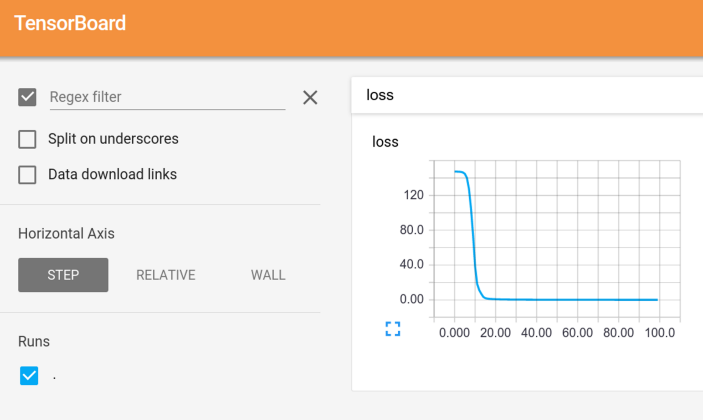
TensorBoard는 TensorFlow에서 제공하는 시각화 도구로, 학습 과정에서의 loss나 weight를 시각화하여 모델의 학습 과정을 분석하는 데 도움을 준다. PyTorch에서도 TensorBoard를 사용할 수 있다.
Summary
PyTorch는 깔끔하고 필수적인 API로 이루어져 있으며 Dynamic computation graph에 최적화되어 있다. 다만 TPU에 적용하기에는 비효율적이며 모바일 기기에 배포하기 쉽지 않다는 단점이 있다.