Likelihood-Free Learning
지금까지 살펴본 모델은 $P_{data}$와 $P_\theta$ 사이의 distance를 KL divergence로 계산한다. 따라서 확률분포나 likelihood를 이용하여 MLE를 통해 학습한다. MLE는 이론적으로 가장 좋은 training objective이지만, 실제로는 높은 likelihood가 좋은 샘플을 보장하지는 않는다. 강의안에서 이러한 경우의 예시를 살펴볼 수 있다.
MLE 대신 실제 샘플의 퀄리티를 높이는 방향으로 학습한다면 훨씬 다양한 모델 아키텍쳐를 시도할 수 있다. 두 확률분포 사이의 거리는 KL divergence가 아닌 다른 방식으로 계산하게 된다.
Two-Sample Test
KL divergence 대신 샘플을 통해 두 확률분포가 유사한지 판단할 수 있다. 두 확률분포에서 샘플을 여러 개 뽑았을 때, 각 샘플이 어느 분포에서 왔는지 구분할 수 없다면 두 확률분포는 유사하다고 판단할 수 있다.
이를 위해 test statistic이라는 통계량을 도입한다.
$T(S_1, S_2) = \left| \cfrac{1}{|S_1|} \sum\limits_{x \in S_1} x - \cfrac{1}{|S_2|} \sum\limits_{x \in S_2} x \right|$
예를 들어, 위와 같이 두 확률분포에서 나온 샘플들의 평균이 유사하다면 두 확률분포는 유사하다고 판단할 수 있다. 따라서 $T(S_1, S_2)$를 최소화하는 것이 training objective가 된다.
실제로는 이 통계량 $T$를 hand-crafting하는 것이 아니라 뉴럴 네트워크인 discriminator $D_\phi$를 통해 구한다. $D_\phi$는 binary classifier로, 특정 이미지가 실제 데이터인지 생성된 데이터인지 판별한다. $D_\phi$의 목표는 binary cross-entropy loss를 최소화하여 두 확률분포를 잘 구분하도록 학습하는 것이다.
$\begin{align*} \max\limits_\phi V(p_{\theta}, D_{\phi}) & = \mathbb{E}_{x \sim p_{\text{data}}} [\log D_{\phi}(x)] + \mathbb{E}_{x \sim p_{\theta}} [\log (1 - D_{\phi}(x))] \\ & \approx \sum\limits_{x \in S_1} \log D_{\phi}(x) + \sum\limits_{x \in S_2} \log (1 - D_{\phi}(x)) \end{align*}$
기댓값 안의 식의 부호를 양수로 만들면 $D_{\phi}$의 목표는 위 식과 같이 $V(p_{\theta}, D_{\phi})$를 최대화하는 것이 된다. 따라서, 위 식을 우리가 원하는 통계량 $T$로 둔다면 $T$를 최소화하는 것은 $D_{\phi}$의 loss를 최대화하는 것이 된다. 즉 discriminator가 두 확률분포를 잘 구분하지 못하는 것이 되므로 생성형 모델이 생성한 이미지가 실제 데이터와 유사하다는 것을 의미한다.
$D_{\theta}^*(\mathbf{x}) = \cfrac{p_{\text{data}}(\mathbf{x})}{p_{\text{data}}(\mathbf{x}) + p_{\theta}(\mathbf{x})}$
Optimal discriminator의 식은 위와 같다. Bayes' rule을 통해 구할 수 있다. $p_{\text{data}}$와 $p_{\theta}$가 같다면 $D_{\theta}^*$의 출력은 언제나 0.5가 되고, 두 분포가 다르다면 $\mathbf{x}$가 $p_{\text{data}}$에 가까울수록 출력이 1에 가까워진다.
Generative Adversarial Networks
최종적인 GAN의 목표는 이러한 discriminator를 속이기 위한 방향으로 generator $G_{\theta}$를 학습하는 것이다. Generator 모델은 latent variable $\mathbf{z}$를 입력받아 데이터 $\mathbf{x}$를 생성하는 모델로, 뉴럴 네트워크의 아키텍쳐에 대한 제약은 없다.
이 generator 모델은 아래와 같이 $p_{\theta}$를 변화시켜 $T$를 최소화하는 것이 목표이다.
$\min\limits_\theta \max\limits_\phi V(G_\theta, D_\phi) = \mathbb{E}_{x \sim p_{\text{data}}} [\log D_\phi(x)] + \mathbb{E}_{\mathbf{z} \sim p(\mathbf{z})} [\log (1 - D_\phi(G_\theta(\mathbf{z})))]$
따라서 최종적인 GAN objective는 위와 같은 minimax game이 된다.
위 식을 분석하기 위해 discriminator가 현재 $G_\theta$에 대해 optimal하다고 가정하면 아래의 식이 된다.
$V(G, D^*_G(\mathbf{x})) = \mathbb{E}_{x \sim p_{\text{data}}} \left[ \log \cfrac{p_{\text{data}}(\mathbf{x})}{p_{\text{data}}(\mathbf{x}) + p_G(\mathbf{x})} \right] + \mathbb{E}_{x \sim p_G} \left[ \log \cfrac{p_G(\mathbf{x})}{p_{\text{data}}(\mathbf{x}) + p_G(\mathbf{x})} \right]$
로그 안 분모를 normalize하기 위해 아래와 같이 변형할 수 있다.
$= \mathbb{E}_{x \sim p_{\text{data}}} \left[ \log \cfrac{p_{\text{data}}(\mathbf{x})}{\cfrac{p_{\text{data}}(\mathbf{x}) + p_G(\mathbf{x})}{2}} \right] + \mathbb{E}_{x \sim p_G} \left[ \log \cfrac{p_G(\mathbf{x})}{\cfrac{p_{\text{data}}(\mathbf{x}) + p_G(\mathbf{x})}{2}} \right] - \log 4$
각 기댓값 항을 KL divergence로 표현할 수 있다.
$= D_{\text{KL}} \left[ p_{\text{data}}, \cfrac{p_{\text{data}} + p_G}{2} \right] + D_{\text{KL}} \left[ p_G, \cfrac{p_{\text{data}} + p_G}{2} \right] - \log 4$
Jenson-Shannon divergence의 정의에 의해 아래와 같이 표현할 수 있다.
$= 2 D_{\text{JS}} [ p_{\text{data}}, p_G ] - \log 4$
즉, $P_{data}$와 $P_\theta$ 사이의 distance를 측정하는 방식을 KL divergence가 아닌 Jenson-Shannon divergence로 바꾼 것이다.
The GAN Training Algorithm
실제로 optimal discriminator $D_{\theta}^*$를 찾는 것은 불가능하기 때문에 GAN을 학습하는 것은 매우 까다롭다. 학습 알고리즘은 아래와 같다.
- 데이터셋에서 $m$개의 mini-batch를 뽑는다.
- $m$개의 noise vector를 생성한 후 generator를 통해 fake sample을 생성한다.
- 위 식을 통해 $V(G_\theta, D_\phi)$를 구하고, gradient ascent를 통해 $\phi$를 한 step 업데이트한다.
- 새로운 $\phi$를 이용해 $V(G_\theta, D_\phi)$를 구하고, gradient descent를 통해 $\theta$를 한 step 업데이트한다.
- 위 과정을 수렴할 때까지 반복한다.
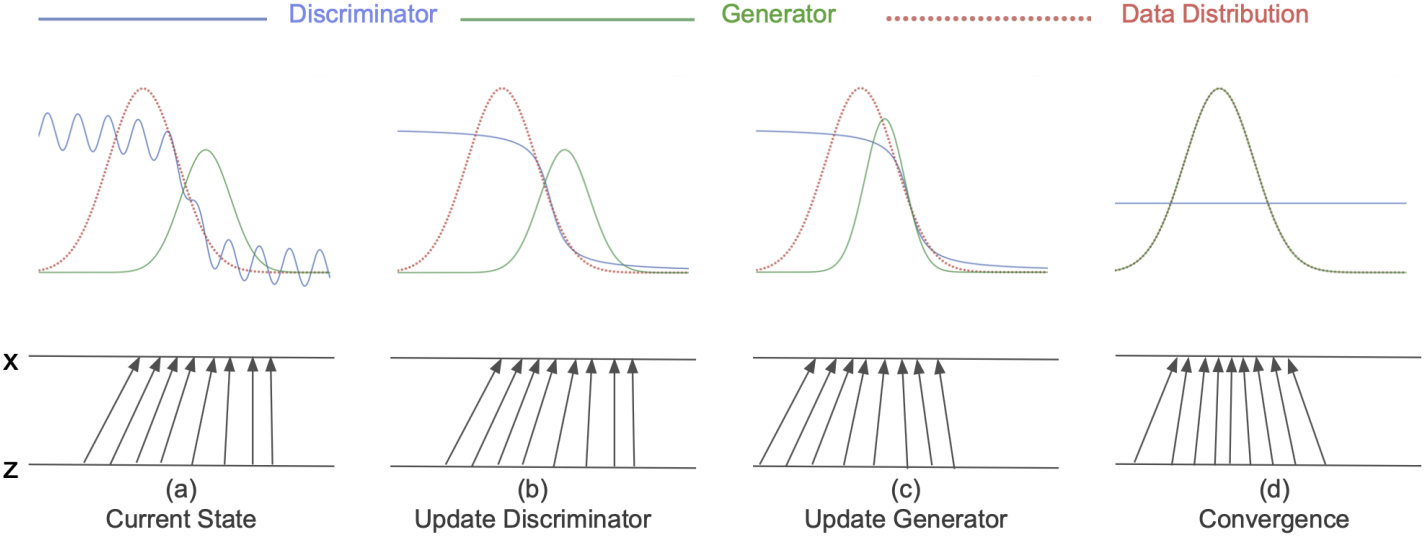
이 학습 과정을 시각화하면 위 그림과 같다.
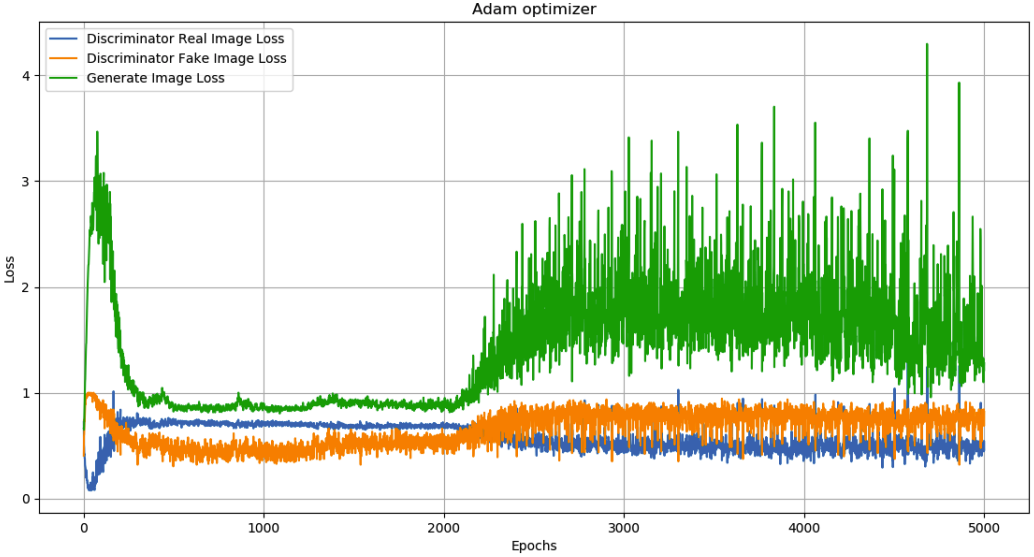
Epoch에 따른 discriminator와 generator의 loss는 위와 같다. 학습이 진행되면서 loss가 수렴하지 않고 진동하기 때문에 언제 학습을 종료할지 정하기가 어렵다.
Mode collapse는 또다른 GAN의 단점 중 하나로, generator가 다양한 샘플을 생성하지 않고 discriminator를 속이기 쉬운 몇 가지의 샘플만을 생성하는 현상이다. KL divergence에서는 $P_{data}$의 값이 있을 때 $P_\theta$의 값이 작으면 loss를 크게 받지만 GAN에서는 이러한 제약이 없기 때문이다.

위 그림은 mode collapse의 예시이다.
이처럼 GAN은 학습이 매우 어렵기 때문에 더이상 SOTA가 아니며, 많은 사람들이 GAN 대신 diffusion model을 사용한다.