Flow Models
Flow model은 VAE와 유사한 latent variable model로, 먼저 latent vector $\mathbf{z}$를 샘플링한 후 이를 이용해 $\mathbf{x}$를 생성하는 방식이다. 하지만 VAE가 뉴럴 네트워크를 이용해 $p_\theta(\mathbf{x})$의 파라미터인 평균과 분산을 추정하고 거기서 다시 $\mathbf{x}$를 샘플링하는 것과 달리, flow model은 deterministic 함수 $\mathbf{x} = f_\theta(\mathbf{z})$를 이용해 $\mathbf{x}$를 바로 생성한다.
학습 시에는, VAE에서는 수많은 $\mathbf{z}$가 $\mathbf{x}$를 생성할 수 있는 확률을 조금이나마 가지고 있기 때문에 $p_\theta(\mathbf{x})$를 구하기 위해서는 모든 가능한 $\mathbf{z}$값에 대한 적분을 수행해야 했고, 이를 회피하기 위해 variational inference와 ELBO를 도입하였다. 그에 반해 flow model에서는 $\mathbf{x}$와 $\mathbf{z}$가 일대일 대응이다. 또한 $p(\mathbf{z})$를 이용해 $p_\theta(\mathbf{x})$를 직접 계산할 수 있기 때문에 MLE를 이용하여 쉽게 학습할 수 있다.
이때 함수 $\mathbf{x} = f_\theta(\mathbf{z})$는 invertible하다. 즉 $\mathbf{x}$와 $\mathbf{z}$가 일대일 대응이 되며, 둘의 dimension이 같다는 의미도 된다.
Change of Variables
Flow model의 기본 개념이 되는 change of variables에 대해 알아보자. $\mathbf{x} = f_\theta(\mathbf{z})$의 관계가 있을 때 $p(\mathbf{z})$를 이용해 $p_\theta(\mathbf{x})$를 직접 계산하는 방법이다.
예를 들어, 스칼라 랜덤변수 $Z$가 uniform distribution $\mathcal{U}[0, 2]$를 따른다고 하자. $p_Z(z) = \cfrac{1}{2}$이 된다.
이때 $X = f(Z) = 4Z$라 하면, $p_X(x)$를 이 변수 간 관계를 이용하여 구할 수 있다. $Z = f^{-1}(X) = h(X)$라 하면 아래의 수식을 만족한다.
$p_X(x) = p_Z(h(x)) \left| h'(x) \right| = p_Z(z) \left| \cfrac{1}{f'(z)} \right|$
따라서 $p_X(x) = p_Z(h(x)) \times \cfrac{1}{4} = \cfrac{1}{8}$이 된다.
다른 예시로 $Z \sim \mathcal{U}[0, 2]$이고 $X = \exp(Z)$라면, $h(X) = \ln(X)$가 되고, $p_X(x) = p_Z(\ln(x)) \left| h'(x) \right| = \cfrac{1}{2x}$가 된다. 이렇게 change of variables를 이용하면 더욱 복잡한 확률분포를 모델링할 수 있다.
이에 대한 증명은 CDF을 이용하면 쉽게 할 수 있다.
$X$와 $Z$가 랜덤벡터이고 $f_\theta$가 nonlinear한 일반적인 경우로 확장하면 아래와 같다.
$p_X(\mathbf{x}) = p_Z \big( \mathbf{f}^{-1}(\mathbf{x}) \big) \left| \det \left( \cfrac{\partial \mathbf{f}^{-1}(\mathbf{x})}{\partial \mathbf{x}} \right) \right| = p_Z(\mathbf{z}) \left| \det \left( \cfrac{\partial \mathbf{f}(\mathbf{z})}{\partial \mathbf{z}} \right) \right|^{-1}$
Jacobian을 이용해 Taylor expansion을 하여 함수를 linear approximation하는 방식이다.
뉴럴 네트워크를 이용해 invertible한 방식으로 $\mathbf{f}_\theta$를 모델링한다면, $\mathbf{x}$로부터 $\mathbf{z}$를 바로 찾을 수 있고 $p_X(\mathbf{x})$로부터 하나로 대응되는 $p_Z(\mathbf{z})$를 바로 찾을 수 있기 때문에 variational inference 없이 바로 MLE를 할 수 있다.
따라서 함수 $\mathbf{f}_\theta$를 잘 모델링하여 inverse를 구하기 쉽고 jacobian도 구하기 쉽도록 해야 한다.
Flow of Transformations
딥러닝에서 단순한 퍼셉트론을 여러 층 쌓아 복잡한 모델을 만들 수 있는 것처럼, 단순한 invertible function을 여러 층 쌓으면 복잡한 transformation을 구현하면서도 전체가 invertible하게 될 수 있다.
$\mathbf{z}_m = \mathbf{f}_{\theta}^{m} \circ \cdots \circ \mathbf{f}_{\theta}^{1}(\mathbf{z}_0) = \mathbf{f}_{\theta}(\mathbf{z}_0)$
$\mathbf{z}_0$는 처음에 직접 샘플링하는 단순한 가우시안과 같은 랜덤벡터이고, 각각의 함수 $\mathbf{f}_{\theta}^{m}$는 단순한 형태의 invertible function이다. 여러 layer를 거쳐 최종적으로 얻은 결과가 $\mathbf{x}$가 된다.
$p_X(\mathbf{x}; \theta) = p_Z \big( \mathbf{f}_{\theta}^{-1}(\mathbf{x}) \big) \prod\limits_{m=1}^{M} \left| \det \left( \cfrac{\partial (\mathbf{f}_{\theta}^{m})^{-1} (\mathbf{z}_m)}{\partial \mathbf{z}_m} \right) \right|$
확률분포를 구하기 위해서는 각 layer에서 change of variables 공식을 적용한다. 각 layer에 대한 jacobian의 determinant를 구할 수 있다면 전체 determinant도 구할 수 있다. 곱의 determinant와 determinant의 곱은 같다는 원리를 이용했다.
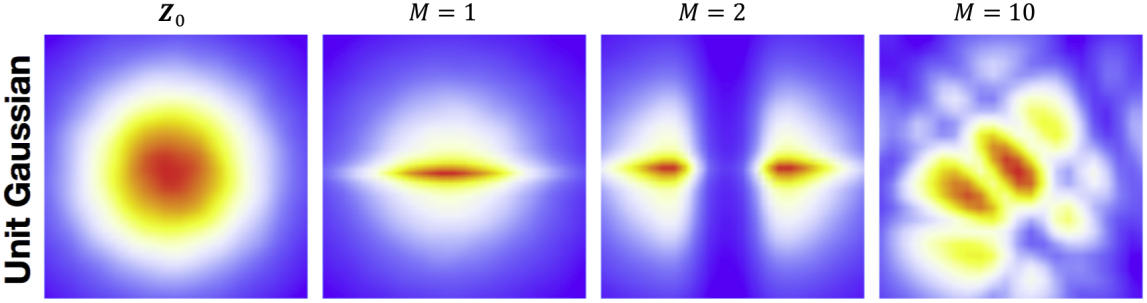
여러 층으로 transformation을 구성했을 때 각 layer의 결과를 시각화하면 위와 같다. 처음에는 unit Gaussian으로 시작했지만 layer를 거칠수록 점점 복잡한 분포로 변해가는 것을 볼 수 있다.
실제로 각 layer를 어떻게 설계할지는 뒤에 살펴볼 각각의 모델마다 차이가 있다.
Learning and Inference
Flow model에서는 직접 likelihood를 구하여 MLE를 할 수 있다.
$\max\limits_{\theta} \log p_X (\mathcal{D}; \theta) = \sum\limits_{\mathbf{x} \in \mathcal{D}} \log p_Z \big( \mathbf{f}_{\theta}^{-1}(\mathbf{x}) \big) + \log \left| \det \left( \cfrac{\partial \mathbf{f}_{\theta}^{-1} (\mathbf{x})}{\partial \mathbf{x}} \right) \right|$
이때 일반적으로 $n \times n$ 행렬의 determinant을 구하는 것은 $O(n^3)$의 복잡도를 가지고 있기 때문에, jacobian 행렬이 특정한 형태를 가지도록 설계해야 한다. 특히, jacobian이 삼각행렬이 된다면 determinant를 $O(n)$의 복잡도로 구할 수 있는데, 단순히 대각 성분을 모두 곱하기만 하면 된다.
$J = \cfrac{\partial \mathbf{f}}{\partial \mathbf{z}} = \begin{pmatrix} \cfrac{\partial f_1}{\partial z_1} & \cdots & 0 \\ \vdots & \ddots & \vdots \\ \cfrac{\partial f_n}{\partial z_1} & \cdots & \cfrac{\partial f_n}{\partial z_n} \end{pmatrix}$
위와 같이 Jacobian이 diagonal의 위쪽이 0인 삼각행렬이 되려면 $f_i(\mathbf{z})$가 $i$ 이전의 $\mathbf{z}$ element에만 dependent해야 한다. 즉 autoregressive model과 유사한 조건이 된다.
Inference는 단순히 prior distribution으로부터 $\mathbf{z}$를 하나 샘플링한 뒤 transformation을 순서대로 거치면 된다. 또한 데이터 $\mathbf{x}$로부터 latent vector $\mathbf{z}$를 알고 싶을 때에도 마찬가지로 inverse transformation을 순서대로 수행하면 된다.