Variational Inference
지난 강의에서, latent variable $\mathbf{z}$의 분포를 임의로 모델링하기 위해 $q(\mathbf{z})$를 도입하였다. 이 $q(\mathbf{z})$를 이용하여 ELBO를 유도하고, 최종 목표인 데이터의 likelihood $p(\mathbf{x})$를 최대화할 수 있다. 이러한 전반적인 과정을 variational inference라고 한다.
이러한 과정이 필요했던 이유는, $\mathbf{z}$로부터 $\mathbf{x}$를 추정하는 모델을 학습시키기 위해서는 $\mathbf{z}$가 주어져야 하는데, 우리가 가진 데이터셋은 $\mathbf{x}$밖에 없기 때문이다. 따라서 우회적인 방법으로 $\mathbf{x}$로부터 $\mathbf{z}$를 추정하는 모델을 도입했는데 그것이 바로 $q(\mathbf{z})$이다.
지난 강의에서 언급했듯 이론상 $q(\mathbf{z}) = p(\mathbf{z} \mid \mathbf{x})$가 되면 ELBO의 등식이 성립하여 optimal한 모델이 된다. 하지만 실제로는 뉴럴 네트워크를 이용하여 $p(\mathbf{z} \mid \mathbf{x})$에 가까이 가기 위한 optimization 문제를 풀게 된다.
두 분포 $q(\mathbf{z})$와 $p(\mathbf{z} \mid \mathbf{x})$ 사이의 KL Divergence를 구해 보자.
$D_{KL}(q(\mathbf{z}) \| p(\mathbf{z} \mid \mathbf{x} ; \theta)) = - \sum\limits_{\mathbf{z}} q(\mathbf{z}) \log p(\mathbf{z}, \mathbf{x} ; \theta) + \log p(\mathbf{x} ; \theta) - H(q) \geq 0$
위 식의 부등호 부분을 아래와 같이 정리할 수 있다.
$\log p(\mathbf{x} ; \theta) \geq \sum\limits_{\mathbf{z}} q(\mathbf{z}) \log p(\mathbf{z}, \mathbf{x} ; \theta) + H(q)$
이전 강의에서의 ELBO 식이 나온다는 것을 알 수 있다. 이처럼 KL Divergence를 이용해서도 ELBO를 최대화하는 것이 $q(\mathbf{z})$가 $p(\mathbf{z} \mid \mathbf{x})$에 가까워지도록 하는 것과 같음을 보일 수 있다.
하지만 문제는 VAE에서는 $p(\mathbf{z} \mid \mathbf{x})$를 직접 구할 수 없다는 것이다. $p(\mathbf{x} \mid \mathbf{z})$가 뉴럴 네트워크로 정의되기 때문에 조건부 확률을 뒤집는 것을 수식적으로 계산할 수 없다. 따라서 VAE에서는 새로운 뉴럴 네트워크를 도입하여 $p(\mathbf{z} \mid \mathbf{x})$를 모델링한다. 이 뉴럴 네트워크의 확률분포를 $q(\mathbf{z} ; \phi)$라 하자.
이때 뉴럴 네트워크 $q(\mathbf{z} ; \phi)$를 VAE의 encoder, $p(\mathbf{x} \mid \mathbf{z} ; \theta)$를 decoder라 한다.
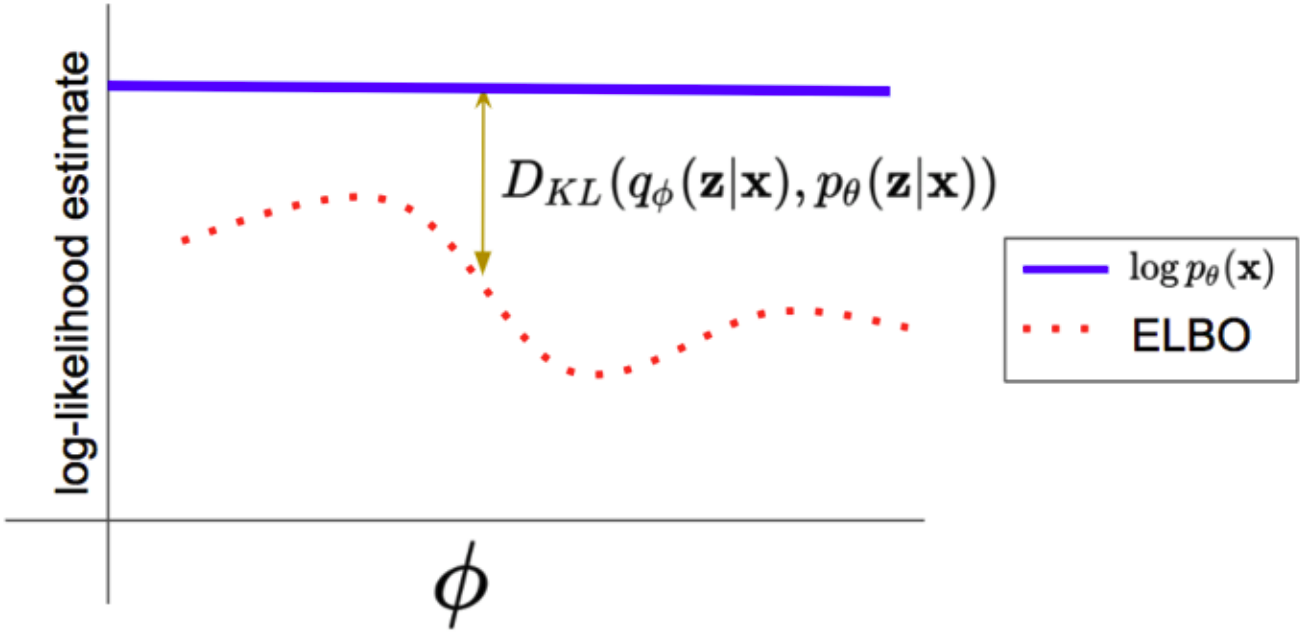
이 optimization 과정을 도식화하면 위와 같다. 어떤 이미지 $\mathbf{x}$와 decoder 파라미터 $\theta$가 주어졌을 때, log probability $\log p_\theta(\mathbf{x})$는 우리가 모르는 어떤 상수이다. $q_\phi(\mathbf{z})$의 파라미터 $\phi$가 변함에 따라 KL Divergence도 변함을 알 수 있다. 따라서 VAE의 전략은 encoder 파라미터 $\phi$와 decoder 파라미터 $\theta$를 joint training하는 것이다.
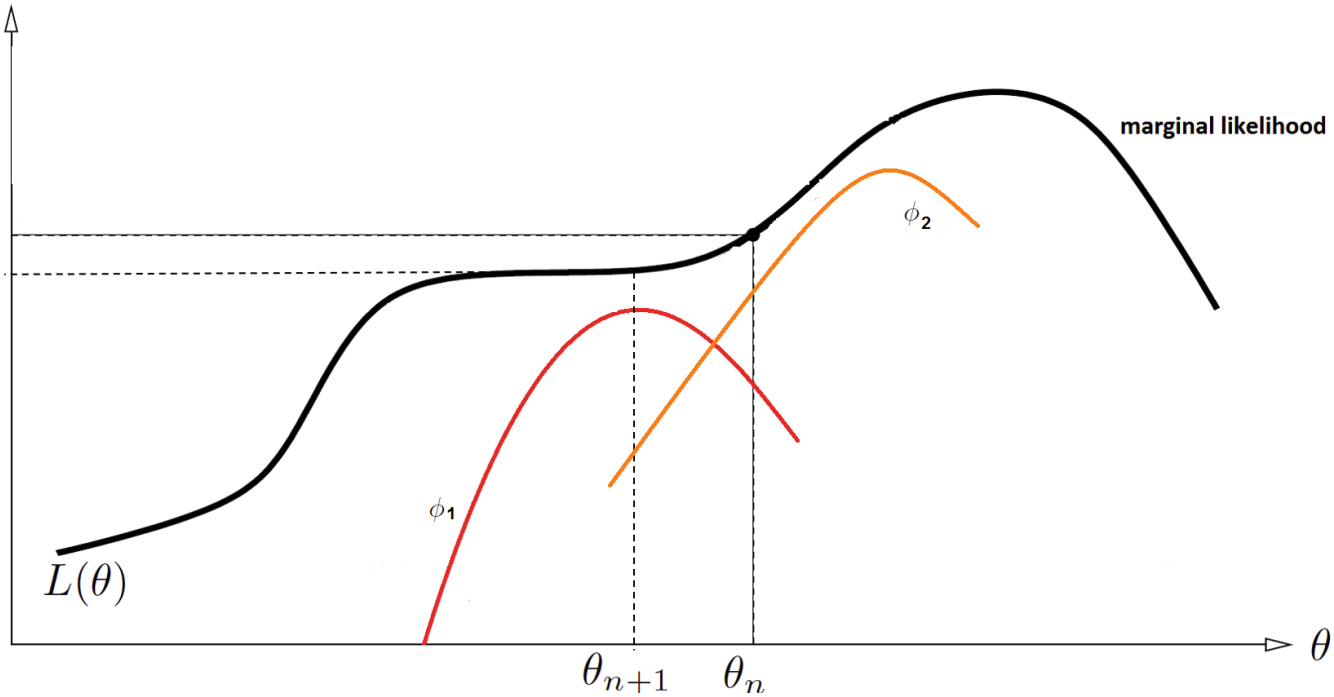
$\phi$와 $\theta$를 동시에 optimization하는 상황을 도식화하면 위와 같다. $\phi$를 통해 실제 marginal likelihood가 높은 곳에 높은 확률분포를 가지도록 곡선을 선택하고, $\theta$는 한 곡선 안에서 실제 marginal likelihood와의 차이가 최소가 되는 지점을 찾는다.
Training over the Entire Dataset
$\ell(\theta ; \mathcal{D}) = \sum\limits_{\mathbf{x}^i \in \mathcal{D}} \log p(\mathbf{x}^i ; \theta) \geq \sum\limits_{\mathbf{x}^i \in \mathcal{D}} \mathcal{L}(\mathbf{x}^i ; \theta, \phi^i)$
전체 데이터셋에 대해 학습하기 위해 위와 같이 각 이미지에 대한 log likelihood의 합으로 objective function을 구성한다. ELBO도 마찬가지로 각 이미지에 대한 값을 모두 합하여 구한다.
이때 ELBO를 정확하게 계산하려면 각 data point $\mathbf{x}^i$에 대해 서로 다른 확률분포 $q(\mathbf{z} ; \phi^i)$가 필요하다는 문제점이 있다. 각 data point마다 그 데이터가 생성되었을 latent vector의 기댓값과 분산이 모두 다를 것이기 때문이다.
그렇기 때문에 실제 VAE에서는 공통된 뉴럴 네트워크로 $q(\mathbf{z} ; \phi)$를 예측하지만, motivation을 위해 아래 두 섹션에서는 $q(\mathbf{z} ; \phi^i)$가 뉴럴 네트워크가 아니라 단순히 변수 $\phi^i$에 의해 정해지는 확률분포로 보자. 즉, $\phi^i_1$이 기댓값, $\phi^i_2$가 분산이 되어 $\mathbf{z}$가 어떤 값이었을지에 대한 확률분포를 각 데이터 $\mathbf{x}^i$에 대해 직접 결정하는 것이다.
Learning via Stochastic Variational Inference (SVI)
$\mathcal{L}(\mathbf{x}^i ; \theta, \phi^i) = \mathbb{E}_{q(\mathbf{z}; \phi^i)} \big[ \log p(\mathbf{z}, \mathbf{x}^i ; \theta) - \log q(\mathbf{z}; \phi^i) \big]$
ELBO를 최대화하기 위한 가장 간단한 방법은 위의 ELBO 식에 대해 gradient ascent를 사용하는 것이다. 먼저 각 파라미터 $\theta, \phi^1, \cdots, \phi^M$을 initialize한다. 이후 $\phi^i$에 대해 먼저 gradient를 구하여 optimization을 진행한다. $\phi^i$가 수렴값에 도달하면 $\theta$를 한 스텝 업데이트한다. 이 과정을 $\theta$가 수렴할 때까지 반복한다.
Reparameterization Trick
이때 $\theta$에 대한 gradient는 구하기 쉬운데, $\phi^i$에 대한 gradient는 직접 구할 수 없다. $\phi^i$로 정의되는 확률분포에서 $\mathbf{z}$를 샘플링하는 과정은 미분이 불가능하기 때문이다. 따라서 Reparameterization trick을 이용하여 이를 해결한다.
Reparameterization trick은 먼저, $q(\mathbf{z}; \phi)$를 기댓값이 $\mu$, 분산이 $\sigma^2I$인 가우시안 분포라고 가정한다. 첨자 $i$는 생략한다. $\phi_1$이 기댓값, $\phi_2$가 분산이 된다. 이 분포에서 샘플을 하나 뽑는 과정을 아래와 같이 두 단계로 나누어 생각할 수 있다.
- $\mathcal{N}(0, I)$에서 샘플 $\epsilon$을 하나 뽑는다.
- $\mathbf{z} = \mu + \sigma\epsilon$을 통해 $\mathbf{z}$를 계산한다.
이 과정을 통해 $\mu$와 $\sigma$가 미분 가능한 방식으로 ELBO에 영향을 미치게 되므로 gradient를 구할 수 있다.
$\displaystyle \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z}; \phi)} [r(\mathbf{z})] = \int q(\mathbf{z}; \phi) r(\mathbf{z}) d\mathbf{z} = \mathbb{E}_{\boldsymbol{\epsilon} \sim \mathcal{N}(0, I)} [r(g(\boldsymbol{\epsilon}; \phi))] = \int \mathcal{N}(\boldsymbol{\epsilon}) r(\mu + \sigma \boldsymbol{\epsilon}) d\boldsymbol{\epsilon}$
수식을 간단히 하기 위해 원래 ELBO 식의 기댓값 안의 식을 $r(\mathbf{z})$로 치환하면 위 식과 같이 쓸 수 있다. 즉 정해진 분포 $\mathcal{N}(0, I)$에 대하여 기댓값을 구하는 것이기 때문에 gradient 계산이 가능하다.
$\nabla_{\phi} \mathbb{E}_{q(\mathbf{z}; \phi)} [r(\mathbf{z})] = \nabla_{\phi} \mathbb{E}_{\boldsymbol{\epsilon}} [r(g(\boldsymbol{\epsilon}; \phi))] = \mathbb{E}_{\boldsymbol{\epsilon}} [\nabla_{\phi} r(g(\boldsymbol{\epsilon}; \phi))]$
위 식과 같이 gradient $\nabla_{\phi}$를 기댓값 연산 전에 계산할 수 있게 된다.
$\mathbb{E}_{\boldsymbol{\epsilon}} [\nabla_{\phi} r(g(\boldsymbol{\epsilon}; \phi))] \approx \cfrac{1}{K} \sum\limits_{k} \nabla_{\phi} r(g(\boldsymbol{\epsilon}^k; \phi))$
이제 Monte Carlo를 이용하여 위 식과 같이 기댓값을 표본평균으로 근사하여 구할 수 있다.
Amortized Inference
지금까지는 각 이미지에 대해 $\phi^i$를 별개로 학습하는 것으로 생각했는데, 이제는 그 대신 $\mathbf{x}^i$를 입력받아 $\phi^i$를 출력하는 공통된 encoder 네트워크를 학습한다. 즉 regression을 수행하는 것으로 생각할 수 있다. 이를 통해 training을 간소화할 수 있다.
따라서, 각 $\phi^i$에 대한 gradient를 구하는 것이 아니라, encoder의 파라미터들에 대한 gradient를 구하게 된다. 편의상 이 encoder의 파라미터를 $\phi$라 하자.
$\mathcal{L}(\mathbf{x}; \theta, \phi) = \mathbb{E}_{q_{\phi}(\mathbf{z} \mid \mathbf{x})} \big[ \log p(\mathbf{z}, \mathbf{x}; \theta) - \log q_{\phi}(\mathbf{z} \mid \mathbf{x}) \big]$
ELBO 식은 위와 같이 다시 쓸 수 있다. 학습 과정은 아래 순서와 같다.
- $\theta$와 $\phi$를 initialize한다.
- 데이터셋으로부터 이미지 $\mathbf{x}^i$를 하나 뽑는다.
- Gradient $\nabla_{\theta} \mathcal{L}(\mathbf{x}^i ; \theta, \phi)$와 $\nabla_{\phi} \mathcal{L}(\mathbf{x}^i ; \theta, \phi)$를 구한다.
- Gradient ascent를 하는 방향으로 $\theta$와 $\phi$를 업데이트한다.
이 과정을 반복하여 $\theta$와 $\phi$를 optimize한다. 즉 위의 SVI에서 $\theta$와 $\phi$를 별개로 학습했던 것과 달리 여기서는 joint training을 한다.
Autoencoder Perspective
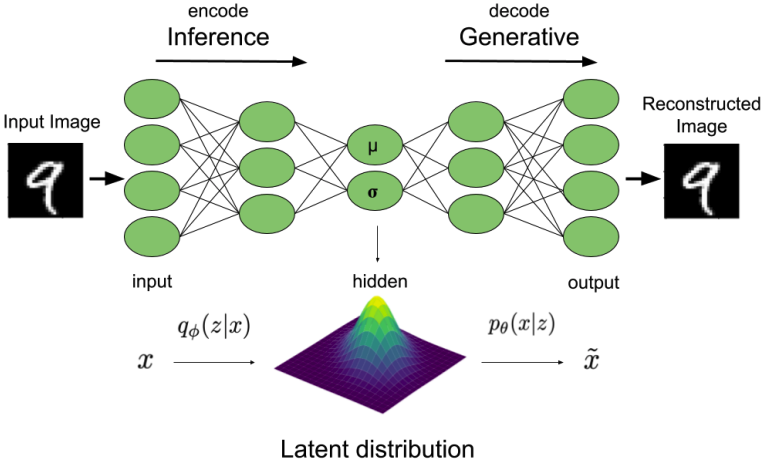
아키텍쳐의 형태로 보면 VAE는 autoencoder와 유사한 점이 많다. 다만 autoencoder는 encoder를 통해 $\mathbf{z}$를 직접 출력하는 반면 VAE는 encoder를 통헤 $\mathbf{z}$의 확률분포 파라미터를 출력하고 그 확률분포로부터 $\mathbf{z}$를 샘플링한다는 차이가 있다.
$\mathcal{L}(\mathbf{x}; \theta, \phi) = \mathbb{E}_{q_{\phi}(\mathbf{z} \mid \mathbf{x})} \big[ \log p(\mathbf{z}, \mathbf{x}; \theta) - \log q_{\phi}(\mathbf{z} \mid \mathbf{x}) \big]$
또한 위의 ELBO 식을 분석해 보면, 첫 번째 log 항은 $q_{\phi}(\mathbf{z} \mid \mathbf{x})$에서 나오는 $\mathbf{z}$값에 대하여 $\log p(\mathbf{z}, \mathbf{x}; \theta)$의 기댓값을 구하는 것이 되고, 두 번째 entropy 항은 확률분포 $q_{\phi}(\mathbf{z} \mid \mathbf{x})$가 최대한 넓게 퍼져서 최대한 다양한 $\mathbf{z}$가 뽑힐 수 있도록 하는 것이다.
$\begin{align*} \mathcal{L}(\mathbf{x}; \theta, \phi) & = \mathbb{E}_{q_{\phi}(\mathbf{z} \mid \mathbf{x})} \big[ \log p(\mathbf{z}, \mathbf{x}; \theta) - \log p(\mathbf{z}) + \log p(\mathbf{z}) - \log q_{\phi}(\mathbf{z} \mid \mathbf{x}) \big] \\ & = \mathbb{E}_{q_{\phi}(\mathbf{z} \mid \mathbf{x})} \big[ \log p(\mathbf{x} \mid \mathbf{z}; \theta) \big] - D_{KL}(q_{\phi}(\mathbf{z} \mid \mathbf{x}) \| p(\mathbf{z})) \end{align*}$
원래 ELBO 식을 변형하여, $\log p(\mathbf{z})$를 빼고 더할 수 있다. 그러면 마지막 식과 같이 decoder 확률분포의 기댓값과 KL Divergence로 식을 나눌 수 있다.
먼저 마지막 식의 첫 번째 항 $\mathbb{E}_{q_{\phi}(\mathbf{z} \mid \mathbf{x})} \big[ \log p(\mathbf{x} \mid \mathbf{z}; \theta) \big]$을 해석해 보면, reconstruction loss로 볼 수 있다. Decoder 파라미터 $\theta$가 주어졌을 때, $\mathbf{z}$로부터 생성한 $\mathbf{x}$가 얼마나 원래 input 이미지와 likely한지를 보는 것이다. 즉 이 첫 번째 항이 autoencoder의 특성을 갖고 있다고 할 수 있다.
두 번째 KL Divergence 항을 보면, 우리가 encoder를 이용해 예측하는 확률분포 $q_{\phi}(\mathbf{z} \mid \mathbf{x})$가 우리가 처음에 설정한 $\mathbf{z}$의 prior, 즉 가우시안 분포 $p(\mathbf{z}) = \mathcal{N}(0, I)$에 가까워지도록 한다. 즉, 첫 번째 항과 두 번째 항이 상호보완적으로 작용하여 $\mathbf{z}$가 가우시안 분포를 따르면서도 다양한 이미지를 생성할 수 있도록 한다.
따라서 VAE가 autoencoder와 다른 점은, $\mathbf{z}$가 아무 분포가 아니라 우리가 원하는 가우시안 분포를 따르도록 학습 시에 강제된다는 것이다.
이 덕분에 inference 시에는 우리가 임의로 $\mathbf{z}$를 샘플링해서 decoder에 넣어 줄 수 있다. 일반 autoencoder의 경우 우리가 임의로 $\mathbf{z}$를 decoder에 넣어 준다고 하더라도 그럴듯한 출력이 생성되지 않을 것이다.