Latent Variable Models: Motivation
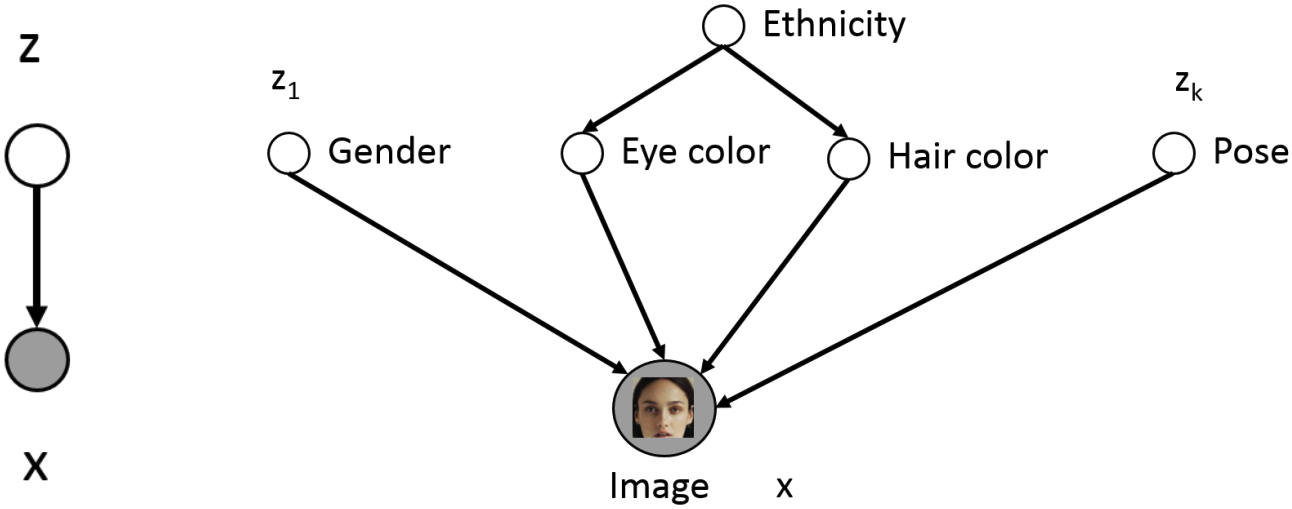
이미지와 같은 고차원 데이터는 실제 픽셀 개수보다 훨씬 적은 개수의 변수들로 설명될 수 있다. 예를 들어 사람 얼굴 사진은 위 그림과 같이 머리카락 색, 자세, 나이 등의 추상적인 개념으로 표현될 수 있다. 이미지와 같은 raw data를 $\mathbf{x}$, 추상적인 여러 개념을 벡터로 모아 $\mathbf{z}$라 한다면, 둘 사이의 인과관계를 위와 같은 그래프 또는 Bayesian network 모델로 나타낼 수 있다.
이미지를 생성해야 하는 입장에서 보면, $\mathbf{x}$에 대한 확률분포 $p(\mathbf{x})$를 처음부터 알아내는 것보다는 추상적인 특징 $\mathbf{z}$가 정해졌을 때 $p(\mathbf{x} \mid \mathbf{z})$를 알아내는 것이 훨씬 간단할 수 있다. 확률분포로 표현해야 할 variability가 훨씬 적기 때문이다. 예를 들어 아무 조건 없이 사람 얼굴 사진을 생성하는 것보다 '검은색 머리, 오른쪽을 보고 웃고 있는 젊은 남성'이라는 조건을 주면 훨씬 쉽게 이미지를 상상할 수 있다.
이러한 $\mathbf{z}$는 데이터셋에서 직접적으로 얻을 수 없는 정보이기 때문에 latent vector라고 부른다.
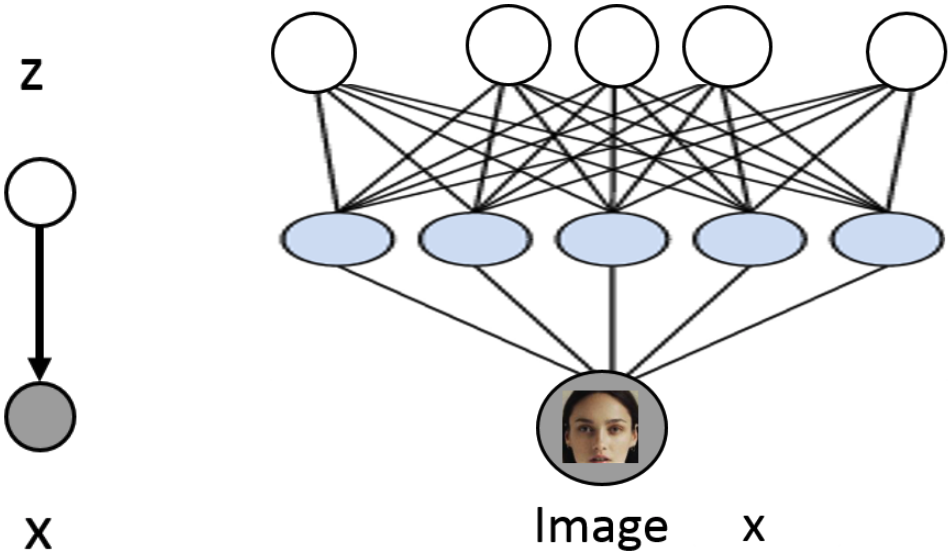
하지만 세상의 모든 사진에 대해 인과관계를 찾고 일일이 확률적으로 모델링하는 것은 매우 어렵다. 따라서 latent variable model의 기본적인 아이디어는 각 추상적 개념을 명시적으로 정하지 말고 $\mathbf{z}$의 각 element가 의미하는 것을 뉴럴 네트워크가 스스로 해석하도록 하는 것이다.
Deep latent variable models는 위 그림처럼 나타낼 수 있다. 위 예시에서 '검은색 머리, 오른쪽을 보고 웃고 있는 젊은 남성'을 지정해준 것처럼, $\mathbf{z}$ 또한 어딘가에서 정해져서 입력되는 것으로 본다. 대신 우리가 하는 것은 $\mathbf{z}$를 입력받아 $p(\mathbf{x} \mid \mathbf{z})$를 예측하는 뉴럴 네트워크를 학습하는 것이다.
예를 들어, $\mathbf{z}$가 가우시안 분포 $\mathcal{N}(0, \mathbf{I})$로부터 샘플링된다고 가정할 수 있다. 확률분포 $p(\mathbf{x} \mid \mathbf{\mathbf{z}})$ 또한 가우시안 분포이고, 그 평균과 분포가 아래 식과 같이 $\mathbf{z}$를 입력받는 뉴럴 네트워크 $\mu_{\theta}$와 $\Sigma_{\theta}$의 출력이 된다고 가정할 수 있다.
$p(\mathbf{x} \mid \mathbf{z}) = \mathcal{N} (\mu_{\theta}(\mathbf{z}), \Sigma_{\theta}(\mathbf{z}))$
이런 식으로, latent variable model의 본질적인 목적은 데이터 $\mathbf{x}$로부터 feature $\mathbf{z}$를 추출한다는 개념이 아니라, 반대로 $\mathbf{z}$는 어딘가에서 랜덤으로 생성되는 것이고 $\mathbf{z}$의 각 element가 $p(\mathbf{x} \mid \mathbf{z})$에 어떻게 영향을 미치는지 그 인과관계를 뉴럴 네트워크로 모델링한다고 봐야 한다.
'검은색 머리, 오른쪽을 보고 웃고 있는 젊은 남성'이라는 조건을 통해 생성해야 할 사진의 variability가 줄어든 것처럼, $\mathbf{z}$가 의미하는 바를 잘 해석할 수 있게 된다면, 우리는 생성해야 하는 이미지의 카테고리를 좁히고 좁혀 위의 가우시안 분포와 같이 매우 단순한 확률분포로도 우리가 원하는 이미지를 표현할 수 있다.
학습이 잘 되었을 때 우리는 $\mathbf{z}$와 $\mathbf{x}$ 사이에 특정한 인과관계를 '발견'하게 되는 것이고, $\mathbf{x}$가 주어졌을 때 $\mathbf{z}$가 무엇이었을지 알 수 있게 된다면, 즉 $p(\mathbf{z} \mid \mathbf{x})$를 의미 있게 모델링할 수 있게 된다면 이것을 representation learning이라고 부를 수 있다.
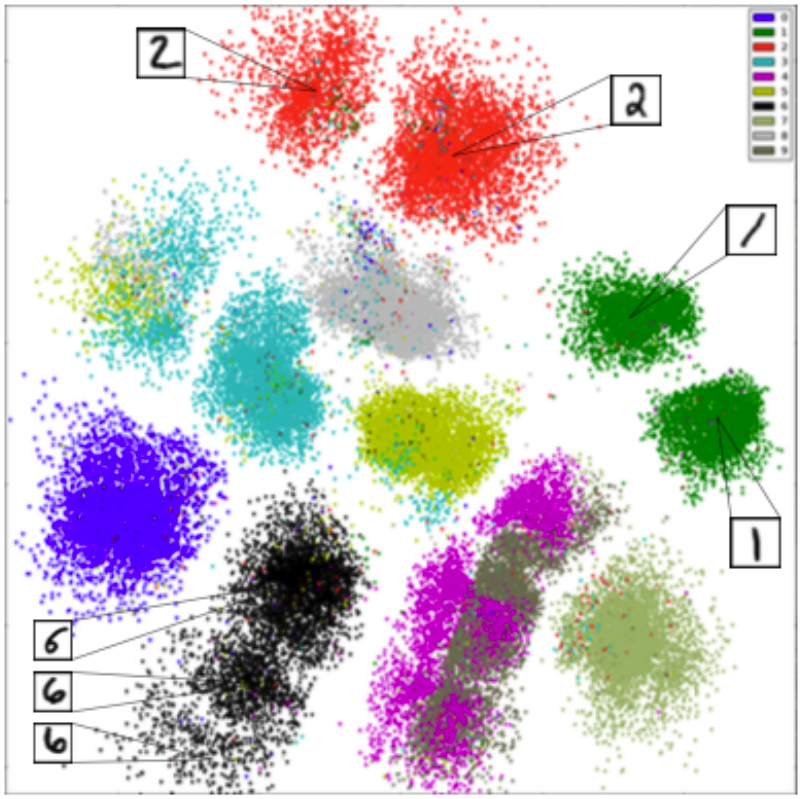
위 그림은 MNIST 데이터셋을 latent space에 표현한 것이다. 이 예시를 통해 $\mathbf{z}$와 $\mathbf{x}$의 관계가 잘 모델링된다면 $p(\mathbf{z} \mid \mathbf{x})$, 즉 각 숫자에 대해 latent vector가 어떻게 clustering되어 분포하고 있는지도 파악할 수 있다는 것을 알 수 있다. 즉 unsupervised learning 또는 representation learning이 된다.
Mixture of Gaussians: a Shallow Latent Variable Model
Variational Autoencoder에 들어가기 앞서 조금 더 간단한 모델인 Mixture of Gaussians에 대해 알아보자.
우선 $\mathbf{z}$에서 $\mathbf{x}$로 가는 Bayesian network $\mathbf{z} \rightarrow \mathbf{x}$를 가정한다. $\mathbf{z}$는 categorical distribution으로, $1$부터 $K$ 중 하나의 값을 가질 수 있다.
$p(\mathbf{x} \mid \mathbf{z} = k) = \mathcal{N} (\mu_k, \Sigma_k), \quad k \in \{1, \cdots, K\}$
$\mathbf{z}$가 어떤 값을 가지는지에 따라 $p(\mathbf{x} \mid \mathbf{z} = k)$의 평균과 분산 값이 달라지는데, 뉴럴 네트워크를 쓰지는 않고 표로 $k$개의 평균과 분산 값이 미리 정해져 있다고 가정한다.
이 모델에서 데이터를 생성하기 위해서는 먼저 categorical distribution에서 $\mathbf{z}$를 샘플링하고, 찾은 $\mu_k$와 $\Sigma_k$ 값을 이용해 $\mathcal{N} (\mu_k, \Sigma_k)$에서 $\mathbf{x}$를 샘플링하면 된다.
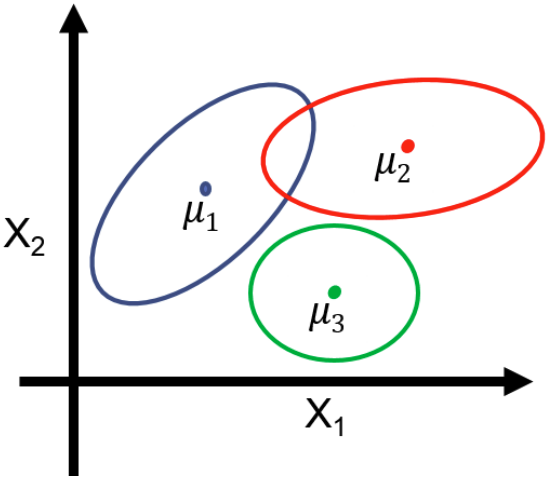
위의 그림을 예로 들면 먼저 1, 2, 3 중에서 $\mathbf{z}$가 될 값을 고른 뒤, 해당하는 평균 $\mu$와 분산 $\Sigma$로부터 $x_1$과 $x_2$를 샘플링하는 것이다.
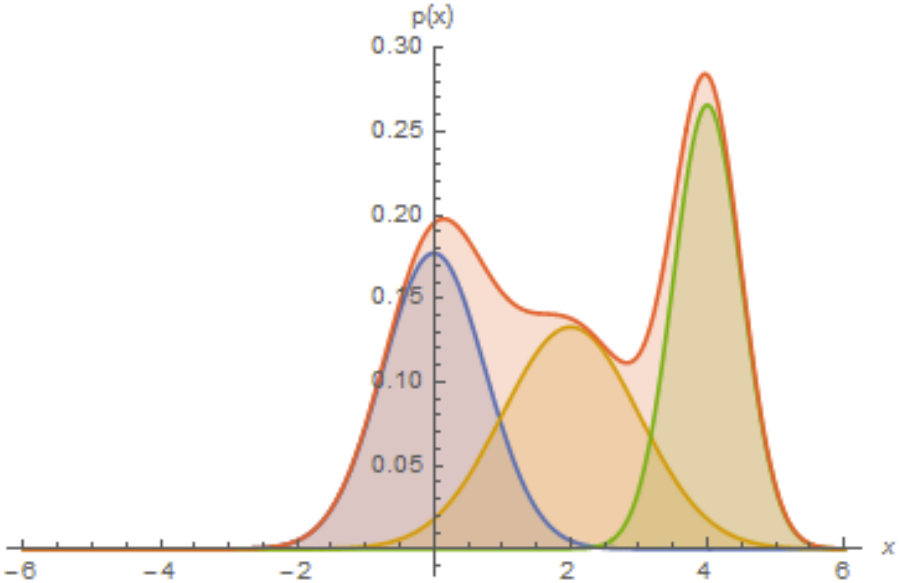
이러한 방법을 통해, 위 그림과 같이 marginal distribution $p(\mathbf{x})$은 충분히 complex하게 표현할 capacity를 갖추면서도 sampling 시에는 하나의 가우시안을 선택하는 간단한 방식을 사용할 수 있다.
Variational Autoencoder
Mixture of Gaussians은 단순한 가우시안 분포를 $K$개 합침으로써 복잡한 확률분포를 모델링하면서도 샘플링을 단순하게 유지할 수 있었다. 한발 더 나아가 VAE에서는 $\mathbf{z}$가 연속적인 값을 가질 수 있다. 즉 무한히 많은 가우시안 분포를 mixture할 수 있는 것이다. 이것이 VAE가 매우 강력한 생성 모델인 이유이다.
예를 들어, $\mathbf{z}$가 가우시안 분포 $\mathcal{N}(0, \mathbf{I})$를 따를 수 있다.
$p(\mathbf{x} \mid \mathbf{z}) = \mathcal{N} (\mu_{\theta}(\mathbf{z}), \Sigma_{\theta}(\mathbf{z}))$
그 후 위와 같이 $p(\mathbf{x} \mid \mathbf{z})$를 가우시안이라고 가정하고 뉴럴 네트워크를 이용하여 평균과 분산을 예측할 수 있다.
지금까지 설명한 내용을 요약하면
- $p(\mathbf{x})$가 아무리 복잡하더라도 VAE에서는 수많은 가우시안 분포의 mixture로 표현할 수 있다.
- 수많은 가우시안 중 하나를 선택하고 그 가우시안 $p(\mathbf{x} \mid \mathbf{z})$에서 새로운 데이터를 생성하는 것으로 볼 수 있다.
- 이때 가우시안을 선택하는 방법이 $\mathbf{z}$를 $\mathcal{N}(0, \mathbf{I})$에서 랜덤으로 샘플링하는 것이다.
Training Variational Autoencoder
이제 이러한 VAE 모델 $\mu_{\theta}$와 $\Sigma_{\theta}$를 학습하는 방법에 대해 알아보자. 우리가 궁극적으로 원하는 것은 여전히 우리가 만든 모델의 확률분포 $p(\mathbf{x}; \theta)$가 실제 확률분포 $p_{data}(\mathbf{x})$에 최대한 가까워지도록 하는 것이다. 따라서 VAE에서도 MLE를 사용하여 모델을 학습한다.
$\log \prod\limits_{\mathbf{x} \in \mathcal{D}} p(\mathbf{x}; \theta) = \sum\limits_{\mathbf{x} \in \mathcal{D}} \log p(\mathbf{x}; \theta)$
즉, 위 식에서 $\prod\limits_{\mathbf{x} \in \mathcal{D}} p(\mathbf{x}; \theta)$를 최대화하는 것이 목적이다. 이때 곱을 합으로 바꾸기 위해 log likelihood를 사용한다.
우리는 joint distribution $p(\mathbf{x}, \mathbf{z}; \theta)$을 이미 알고 있다. 아래 식과 같이 Bayes rule에 따라 $\mathbf{z}$가 생성되는 가우시안 분포 $\mathcal{N}(0, \mathbf{I})$와 뉴럴 네트워크가 예측하는 조건부 확률분포 $\mathcal{N} (\mu_{\theta}(\mathbf{z}), \Sigma_{\theta}(\mathbf{z}))$를 곱하면 된다.
$p(\mathbf{x}, \mathbf{z}; \theta) = p(\mathbf{x} \mid \mathbf{z}; \theta) p(\mathbf{z})$
이 joint distribution을 이용해 특정 데이터 $\bar{\mathbf{x}}$가 나올 확률 $p(\mathbf{X} = \bar{\mathbf{x}}; \theta)$를 구할 수 있다. 이때 training time에는 데이터 $\mathbf{x}$만 있고 $\mathbf{z}$의 값을 모르기 때문에 아래와 같이 모든 가능한 $\mathbf{z}$ 값에 대해 $p(\bar{\mathbf{x}}, \mathbf{z}; \theta)$를 합하여 marginal distribution을 구해야 한다.
$p(\mathbf{X} = \bar{\mathbf{x}}) = \sum\limits_{\mathbf{z}} p(\bar{\mathbf{x}}, \mathbf{z}; \theta)$
따라서 최종적으로 아래와 같이 표현할 수 있다.
$\hat{\theta} = \arg\max\limits_\theta \sum\limits_{\mathbf{x} \in \mathcal{D}} \log \left( \sum\limits_{\mathbf{z}} p(\mathbf{x}, \mathbf{z}; \theta) \right)$
하지만 $\mathbf{z}$ 값이 연속적이기 때문에 log 안의 합 $\sum\limits_{\mathbf{z}} p(\mathbf{x}, \mathbf{z}; \theta)$을 직접 계산하는 것은 불가능하다. 따라서 학습 시에는 이 값을 추측해야 한다. 이를 추측하기 위한 접근법들을 살펴보자.
First Attempt: Naive Monte Carlo
가장 단순한 방법은 Monte Carlo로, 모든 $\mathbf{z}$의 합을 구하는 대신 샘플을 몇 개 뽑아서 그 값을 추정하는 것이다.
$\sum\limits_{\mathbf{z}} p_{\theta}(\mathbf{x}, \mathbf{z}) = |\mathcal{Z}| \sum\limits_{\mathbf{z} \in \mathcal{Z}} \cfrac{1}{|\mathcal{Z}|} p_{\theta}(\mathbf{x}, \mathbf{z}) = |\mathcal{Z}| \mathbb{E}_{\mathbf{z} \sim \text{Uniform}(\mathcal{Z})} \big[ p_{\theta}(\mathbf{x}, \mathbf{z}) \big]$
위와 같이 식을 쓸 수 있는데, 이때 $\mathcal{Z}$는 가능한 모든 $\mathbf{z}$의 집합이다. $\mathbf{z}$를 곱하고 나누어 기댓값을 만듦으로써 이를 표본평균으로 대체할 수 있다. 이때, $\sum\limits_{\mathbf{z} \in \mathcal{Z}}$ 안을 보면 모든 $\mathbf{z}$에 대한 확률에 $\cfrac{1}{|\mathcal{Z}|}$을 곱하는 형태가 되므로 이것은 $\mathbf{z}$가 uniform distribution을 따른다고 가정하는 꼴이 된다.
$\mathbb{E}_{\mathbf{z} \sim \text{Uniform}(\mathcal{Z})} \big[ p_{\theta}(\mathbf{x}, \mathbf{z}) \big] \approx \cfrac{1}{k} \sum\limits_{j=1}^{k} p_{\theta}(\mathbf{x}, \mathbf{z}^{(j)})$
샘플 $k$개를 뽑는다고 가정할 때 위 식을 통해 기댓값을 예측할 수 있다.
이 방법은 단순하고 unbiased이지만 실제로 사용할 수 없다. 그 이유는 $\mathbf{z}$가 uniform distribution을 따른다는 가정 때문인데, 실제로 현실에 존재하는 데이터를 생성하는 latent vector는 그렇지 않은 latent vector에 비해 훨씬 적기 때문이다. 따라서 uniform하게 $\mathbf{z}$를 샘플링하면 거의 대부분 의미가 없는 $\mathbf{z}$가 나올 것이다.
따라서 $\mathbf{z}$를 샘플링하는 더 나은 방법이 필요하다.
Second attempt: Importance Sampling
Importance sampling을 이용해서 $\sum\limits_{\mathbf{z}} p_{\theta}(\mathbf{x}, \mathbf{z})$를 예측할 수 있다. $q(\mathbf{z})$가 우리가 임의로 정한 $\mathbf{z}$에 대한 어떤 확률분포라 하자.
$\sum\limits_{\mathbf{z}} p_{\theta}(\mathbf{x}, \mathbf{z}) = \sum\limits_{\mathbf{z} \in \mathcal{Z}} \cfrac{q(\mathbf{z})}{q(\mathbf{z})} p_{\theta}(\mathbf{x}, \mathbf{z}) = \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} \right]$
앞선 Monte Carlo 방식에서 달라진 점은 $\cfrac{1}{|\mathcal{Z}|}$을 $q(\mathbf{z})$로 대체한 것이다. 이제 위의 Monte Carlo와 동일하게 $q(\mathbf{z})$에서 샘플을 뽑고 표본평균을 구한다.
$\mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} \right] \approx \cfrac{1}{k} \sum\limits_{j=1}^{k} \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z}^{(j)})}{q(\mathbf{z}^{(j)})}$
이 또한 unbiased이므로 아래의 수식이 성립한다. 표본평균의 기댓값은 실제 평균과 같다는 원리이다.
$\mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} \right] = \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \cfrac{1}{k} \sum\limits_{j=1}^{k} \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z}^{(j)})}{q(\mathbf{z}^{(j)})} \right]$
그렇다면 $q(\mathbf{z})$를 어떻게 골라야 할까? 실제로 가능성이 있는 $\mathbf{z}$에 높은 확률을 주도록 골라야 한다.
Evidence Lower Bound
지금까지 전개한 수식을 정리하면 아래와 같다.
$p_{\theta}(\mathbf{x}) = \sum\limits_{\mathbf{z}} p_{\theta}(\mathbf{x}, \mathbf{z}) = \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} \right] = \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \cfrac{1}{k} \sum\limits_{j=1}^{k} \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z}^{(j)})}{q(\mathbf{z}^{(j)})} \right]$
다시 한 번 training objective인 MLE를 살펴보면 우리는 log likelihood가 필요하다. 맨 왼쪽 항과 맨 오른쪽 항에 각각 $\log$를 취해 보자.
$\log p_{\theta}(\mathbf{x}) = \log \left( \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \cfrac{1}{k} \sum\limits_{j=1}^{k} \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z}^{(j)})}{q(\mathbf{z}^{(j)})} \right] \right) \neq \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \log \left( \cfrac{1}{k} \sum\limits_{j=1}^{k} \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z}^{(j)})}{q(\mathbf{z}^{(j)})} \right) \right]$
그런데 한 가지 문제가 발생한다. 어찌 됐건 우리는 $\mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})}$를 직접 구할 수 없으니 샘플을 뽑아 Monte Carlo 식으로 값을 유추해야 하는데, 그러려면 unbiased estimator가 되어야 한다. 기댓값이 가장 바깥에 있으면 unbiased인데, $\log$는 비선형함수이므로 $\log$가 기댓값의 바깥에 있으면 linearity가 깨지게 되고 bias가 생긴다. 즉, $\neq$ 오른쪽의 식이 우리가 Monte Carlo를 통해 구할 수 있는 unbiased estimate 값이다.
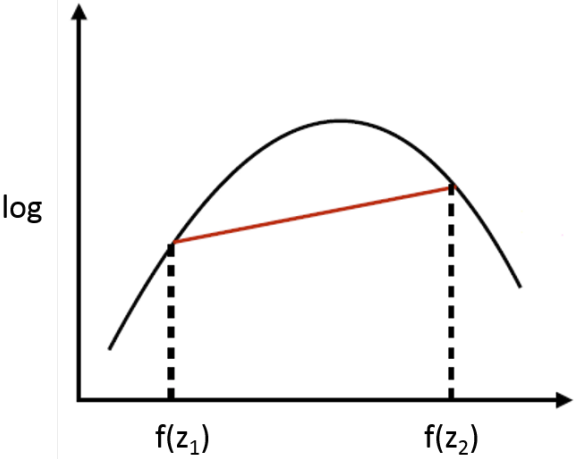
하지만 우리는 $\log$ 함수가 위로 볼록한 함수라는 것을 안다. 즉, 아래의 볼록함수의 정의가 성립한다.
$\log (p x_1 + (1 - p) x_2) \geq p \log (x_1) + (1 - p) \log (x_2)$
이를 임의의 개수의 점들에 대해 확장한 것이 Jenson Inequality이고, 아래와 같이 쓸 수 있다.
$\log \big( \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} [ f(\mathbf{z}) ] \big) = \log \Big( \sum\limits_{\mathbf{z}} q(\mathbf{z}) f(\mathbf{z}) \Big) \geq \sum\limits_{\mathbf{z}} q(\mathbf{z}) \log f(\mathbf{z})$
우리의 경우 $f(\mathbf{z}) = \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z}^{(j)})}{q(\mathbf{z}^{(j)})}$인 것이다.
따라서, Jenson Inequality를 이용해 위 $\neq$를 부등호로 바꿀 수 있다.
$\log \left( \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \cfrac{1}{k} \sum\limits_{j=1}^{k} \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z}^{(j)})}{q(\mathbf{z}^{(j)})} \right] \right) \geq \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \log \left( \cfrac{1}{k} \sum\limits_{j=1}^{k} \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z}^{(j)})}{q(\mathbf{z}^{(j)})} \right) \right]$
따라서, 우변의 항은 우리가 원하는 log likelihood의 lower bound가 된다. 이를 Evidence Lower Bound (ELBO)라 한다. 이 ELBO를 최대화함으로써 우리가 원하는 log likelihood를 간접적으로 최대화할 수 있다.
그리고 $q(\mathbf{z})$를 어떻게 선택하는지에 따라 두 값의 간격이 결정되는데, 그 간격이 작을수록 $q(\mathbf{z})$가 실제 $\mathbf{z}$의 분포를 잘 모델링하고 있다는 뜻이 된다.
참고로 $q = p_{\theta}(\mathbf{z} \mid \mathbf{x})$가 되면 위 부등호의 등호가 성립한다. 그 이유는 아래 식에서 볼 수 있듯 Bayes rule을 사용하면 기댓값 안의 식이 $p_{\theta}(\mathbf{x})$가 되기 때문이다.
$\begin{align*}p_{\theta}(\mathbf{x}) & = \mathbb{E}_{\mathbf{z} \sim q(\mathbf{z})} \left[ \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} \right] \\ \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z})}{q(\mathbf{z})} & = \cfrac{p_{\theta}(\mathbf{x}, \mathbf{z})}{p_{\theta}(\mathbf{z} \mid \mathbf{x})} = \cfrac{p_{\theta}(\mathbf{z} \mid \mathbf{x}) p_{\theta}(\mathbf{x})}{p_{\theta}(\mathbf{z} \mid \mathbf{x})} \\ & = p_{\theta}(\mathbf{x}) \end{align*}$
이를 직관적으로 설명하면, 데이터를 생성한 바로 그 latent vector들을 그대로 사용하면 데이터의 확률분포 $p_{\theta}(\mathbf{x})$도 정확히 모델링할 수 있다는 것이다. 다만 $p_{\theta}(\mathbf{z} \mid \mathbf{x})$를 직접 구한다는 것은 다시 원점으로 돌아가는 것이고, 우리는 우리가 가진 데이터셋만을 이용해서 ELBO를 maximize하는 $q(\mathbf{z})$를 찾는 수밖에 없다.