Maximum Likelihood Estimate
Generative AI의 관점에서는 세상의 모든 데이터는 우리가 모르는 어떤 확률분포 $P_{data}$로부터 샘플링된 것이라고 가정한다. 뉴럴 네트워크 $P_{\theta}$가 최대한 $P_{data}$에 가까워지도록 파라미터를 학습할 때, 가장 기본적인 방법론은 maximum likelihood estimation (MLE)이다.
MLE의 기본적인 아이디어는 데이터들과 model family가 있는 상황에서, model family(뉴럴 네트워크)의 파라미터가 무엇일 때 그 확률분포로부터 이 데이터들이 나왔을 가능성(likelihood)이 가장 높은지를 찾는 것이다. Model family의 파라미터가 $\theta$라면 likelihood가 $\theta$의 함수가 될 것이고, 이를 최대화하는 $\theta$값을 찾는 것이다.
이때 각 데이터는 independent and identically distributed (IID)라 가정한다.
한 가지 쉬운 예시로 biased coin flip을 들 수 있다. Head $H$가 나올 확률이 $\theta$인 동전이 있다고 가정하자. 우리는 coin flip을 Bernoulli distribution으로 모델링할 수 있다. 즉, model family가 $\text{Bernoulli}(\theta)$가 된다.
$\begin{align*} P_{\theta}(x = H) & = \theta \\ P_{\theta}(x = T) & = 1 - \theta \end{align*}$
우리에게 주어진 데이터가 $\{H, H, T, H, T\}$라 하자. 이때 $\theta$가 몇이어야 우리가 가진 데이터가 나올 확률이 가장 높을까? 이 질문에 대한 답이 MLE이다.
각 시행은 IID이므로 위 데이터셋대로 결과가 나올 확률은 아래와 같다.
$\prod\limits_{i} P_{\theta}(x_i) = \theta \cdot \theta \cdot (1 - \theta) \cdot \theta \cdot (1 - \theta)$
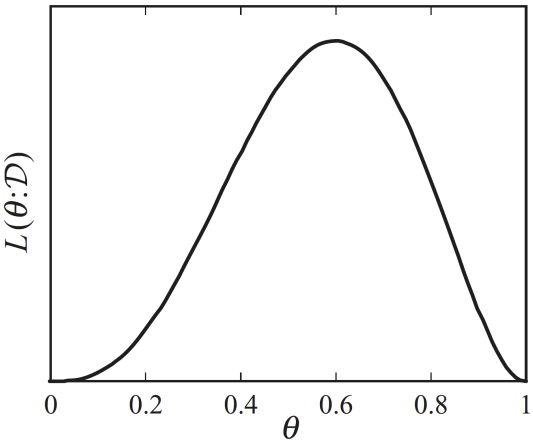
그리고 위 식을 최대화하는 $\theta$ 값은 위 그래프에서도 볼 수 있듯 0.6이다. 이것이 MLE를 수행하는 흐름이다.
$P_{\theta}(\mathbf{x}) = \prod\limits_{i=1}^{n} p_{\text{neural}}(x_i \mid \mathbf{x}_{<i}; \theta_i)$
Autoregressive model의 경우 이미지 등 하나의 high-dimensional data에 대한 확률을 위 식과 같이 순차적으로 계산하기 때문에, 각 element에 대한 조건부 확률을 모두 곱하여 data point 하나에 대한 확률 $P_{\theta}(\mathbf{x})$를 구할 수 있다.
KL-Divergence
생성형 모델의 최종 목적은 결국 $P_{\theta}$가 최대한 $P_{data}$에 가까워지도록 하는 것인데, autoregressive model의 경우 likelihood를 바로 얻을 수 있으므로 이를 사용한다. 확률분포와 likelihood 함수는 이름만 다를 뿐 수학적으로 같은 함수이기 때문이다. 두 확률분포를 정보이론적으로 비교할 수 있는 방법으로 KL-divergence가 있는데, 그 식은 아래와 같다.
$D(p \parallel q) = \sum\limits_{x} p(x) \log \cfrac{p(x)}{q(x)}$
위 식은 항상 0 이상이며, 특히 $p = q$일 때만 위 식이 0이 된다. 또한 $D(p \parallel q) \neq D(q \parallel p)$ 로, assymetric한 특징이 있다.
위 식을 $P_{data}$와 $P_{\theta}$에 적용하면 아래와 같다.
$D(P_{\text{data}} \parallel P_{\theta}) = \sum\limits_{x} P_{\text{data}}(x) \log \cfrac{P_{\text{data}}(x)}{P_{\theta}(x)} = \mathbb{E}_{x \sim P_{\text{data}}} \left[ \log \left( \cfrac{P_{\text{data}}(x)}{P_{\theta}(x)} \right) \right]$
이때 생각해볼 점은, $P_{data}$와 $P_{\theta}$의 자리를 바꿔서 $D(P_{\theta} \parallel P_{\text{data}})$를 사용한다면 뉴럴 네트워크가 생성하는 이미지의 pool 자체를 줄여 버리고 유사한 이미지만 생성하는 mode-seeking behavior를 보일 수 있다. 특정 $x$에 대해 $P_{\text{data}}(x)$ 값이 있더라도 $P_{\theta}(x)$ 값을 줄여 버리면 $D(P_{\theta} \parallel P_{\text{data}})$ 값을 줄일 수 있기 때문이다. 이를 reverse KL-divergence라 한다.
$D(P_{\text{data}} \parallel P_{\theta})$를 사용하면, $P_{\theta}(x)$ 값이 너무 작으면 $D(P_{\text{data}} \parallel P_{\theta})$가 커지기 때문에 확률분포가 전체 space에 고르게 퍼져 뉴럴 네트워크가 최대한 다양한 이미지들을 골고루 생성할 수 있도록 한다.
$\begin{align*} D(P_{\text{data}} \parallel P_{\theta}) & = \mathbb{E}_{x \sim P_{\text{data}}} \left[ \log \cfrac{P_{\text{data}}(x)}{P_{\theta}(x)} \right] \\ & = \mathbb{E}_{x \sim P_{\text{data}}} [\log P_{\text{data}}(x)] - \mathbb{E}_{x \sim P_{\text{data}}} [\log P_{\theta}(x)] \end{align*}$
$D(P_{\text{data}} \parallel P_{\theta})$ 식을 위와 같이 풀 수 있다. 이때 첫 번째 항은 $\theta$와 관련이 없기 때문에, KL-divergence를 minimize하는 입장에서는 두 번째 항만 최소화하면 된다. 결국 $\mathbb{E}_{x \sim P_{\text{data}}} [\log P_{\theta}(x)]$를 최대화해야 하고, 이것은 MLE 문제가 된다.
하지만 여전히 기댓값 $\mathbb{E}$를 $P_{\text{data}}$에 대해 취해야 한다는 문제가 있다. 여기서는 우리가 가진 데이터셋이 전체 data space를 충분히 cover한다고 가정하고 데이터셋에 대한 sample average로 기댓값을 대체할 수 있다.
$\mathbb{E}_{\mathcal{D}} [\log P_{\theta}(x)] = \cfrac{1}{|\mathcal{D}|} \sum\limits_{x \in \mathcal{D}} \log P_{\theta}(x)$
전체 데이터의 집합을 $\mathcal{D}$라 할 때 $\mathbb{E}_{x \sim P_{\text{data}}} [\log P_{\theta}(x)]$를 위 식으로 대체할 수 있다. IID 가정이 있기 때문에 위 식을 최대화하는 것은 likelihood $P_{\theta}(x^{(1)}, \dots, x^{(m)}) = \prod\limits_{x \in \mathcal{D}} P_{\theta}(x)$을 최대화하는 것과 같다.
결국, $P_{data}$와 $P_{\theta}$간의 차이를 줄이는 것과 MLE는 서로 같은 것을 하는 것이다.
Bias-Variance Tradeoff
Autoregressive model도 overfit할 수 있게 때문에 bias-variance tradeoff가 중요하다. 너무 단순한 모델을 사용하거나 conditional independence를 너무 강하게 적용하는 등 hypothesis space를 제한하면 데이터셋이 아무리 커도 $P_{\text{data}}$를 잘 표현하지 못할 수 있는데, 이를 bias라고 한다.
반대로 너무 representation power가 큰 모델을 선택하면 데이터셋에 overfit하여 입력의 작은 변화에도 출력이 매우 크게 변할 수 있는데, 이를 variance라고 한다.