Motivating Example: MNIST
위의 MNIST 데이터셋과 같이 0부터 9까지의 숫자 이미지를 생성하는 모델을 생각해 보자. 이때 각 픽셀 값은 0 또는 1로 binarized되었다고 가정한다. 이미지의 크기가 $24 \times 24$이므로 생성해야 하는 데이터는 $\{x_1, x_2, ..., x_{784}\} \in \{0, 1\}^{784}$이다. 여기서의 목표는 training data와 비슷하지만 새로운 이미지를 생성하는 것이다.
이러한 데이터 생성을 위한 모델을 구축하는 것은 두 단계로 이루어지는데, 첫 번째로 model family $p_{\theta}(x), \theta \in \Theta$를 선정해야 한다. 이후 training data를 이용하여 최적의 파라미터 $\theta$를 찾는다. 이번 강의에서는 model family 중 가장 간단한 autoregressive model에 대해 알아보고, 다음 강의에서는 이 모델을 어떻게 학습할 것인지를 다룬다.
Autoregressive Models
Autoregressive model은 chain rule을 기반으로 하는 생성형 모델이다. 생성하고자 하는 데이터가 $\{x_1, x_2, ..., x_n\}$일 때, chain rule을 사용하면 아래와 같이 표현할 수 있다.
$P(x_1, x_2, \cdots, x_n) = P(x_1) P(x_2 \mid x_1) P(x_3 \mid x_1, x_2) \cdots P(x_n \mid x_1, x_2, \cdots, x_{n-1})$
즉, 이미지와 같이 복잡한 데이터를 생성해야 할 때, 이를 chain rule로 쪼개어 단계별로 한 번에 하나의 값만을 생성한다. 이때 직접 구하기 어려운 복잡한 확률분포들을 neural network로 대신하여 아래와 같이 표현할 수 있다.
$P(x_1, x_2, \cdots, x_n) = P(x_1;\alpha^1) P_\text{neural}(x_2 \mid x_1;\alpha^2) P_\text{neural}(x_3 \mid x_1,x_2;\alpha^3) \cdots$
이때 $\{\alpha^1, \alpha^2, \cdots\}$는 각 네트워크의 파라미터이다.
이러한 모델의 데이터 생성 과정은 아래와 같다.
- 첫 픽셀의 값은 아래와 같이 직접 $\alpha^1$을 지정하여 베르누이 분포로 샘플링할 수 있다.
- 두 번째 픽셀값에 대한 확률값은 첫 번째 픽셀값을 임의의 뉴럴 네트워크 $\psi_1$에 입력하여 구한다. 이 확률값을 베르누이 분포로 하여 두 번째 픽셀값을 샘플링한다.
- 세 번째 픽셀값에 대한 확률값은 첫 번째와 두 번째 픽셀값을 임의의 뉴럴 네트워크 $\psi_2$에 입력하여 구한다. 이 확률값을 베르누이 분포로 하여 세 번째 픽셀값을 샘플링한다.
- 이 과정을 $x_n$을 샘플링할 때까지 반복한다.
$P(X_1 = 1;\alpha^1) = \alpha^1, P(X_1 = 0;\alpha^1) = 1 - \alpha^1$
$P_\text{neural}(X_2 = 1 \mid x_1;\alpha^2) = \psi_1(x_1)$
$P_\text{neural}(X_3 = 1 \mid x_1,x_2;\alpha^3) = \psi_2(x_1, x_2)$
네트워크가 한 번에 하나의 숫자만을 출력하기 때문에 generation 문제를 우리가 풀 수 있는 classification이나 regression 문제로 접근할 수 있다.
한 가지 짚고 넘어갈 것은 데이터의 순서인데, chain rule의 정의상 $\{x_1, x_2, ..., x_n\}$가 어떤 순서로 쪼개져도 수학적으로는 아무 문제가 없다. 하지만 순서가 있는 text나 audio 데이터는 시간 순으로 chain rule을 적용하는 것이 일반적이다. 이미지의 경우 time dependency는 없지만 일반적으로 왼쪽에서 오른쪽, 위에서 아래로 순차적으로 chain rule을 적용한다.
Fully Visible Sigmoid Belief Network (FVSBN)
가장 간단한 autoregressive model의 형태로 FVSBN이 있다. 이 모델은 $P_\text{neural}$ 부분이 뉴럴 네트워크가 아닌 단순한 logistic regression이다.
즉, 위의 $\psi_1(x_1)$와 $\psi_2(x_1, x_2)$를 아래와 같이 쓸 수 있다.
$\begin{align*} \psi_1(x_1) &= \sigma(\alpha_0^2 + \alpha_1^2x_1) \\ \psi_1(x_2) &= \sigma(\alpha_0^3 + \alpha_1^3x_1 + \alpha_2^3x_2) \end{align*}$
이를 일반화하면 $i$번째 데이터 $x_i$에 대해 예측한 확률값 $\hat{x_i}$는 아래와 같다.
$\hat{x}_i = P(X_i = 1 \mid x_1, \cdots, x_{i-1}; \alpha^i) = \sigma\left(\alpha_0^i + \sum\limits_{j=1}^{i-1} \alpha_j^i x_j\right)$
FVSBN은 각 데이터마다 별개의 파라미터 $\alpha^i$를 가지고 있어야 하기 때문에 파라미터의 수가 생성해야 하는 데이터 수의 제곱 단위로 커진다는 문제가 있다. 또한 모델의 복잡도가 낮아 생성한 이미지의 퀄리티가 그렇게 좋지 않다는 단점이 있다.
Neural Autoregressive Density Estimation (NADE)
NADE는 FVSBN의 logistic regression 대신 one-layer neural network를 사용한 모델이다.
$h_i = \sigma(A_ix_{1:i-1} + c_i)$
$\hat{x}_i = P(X_i = 1 \mid x_1, \cdots, x_{i-1}; A_i, c_i, \alpha_i, b_i) = \sigma(\alpha_ih_i + b_i)$
$\hat{x}_i$를 확률로 하는 베르누이 분포에서 $x_i$를 샘플링함으로써 데이터를 생성할 수 있다.
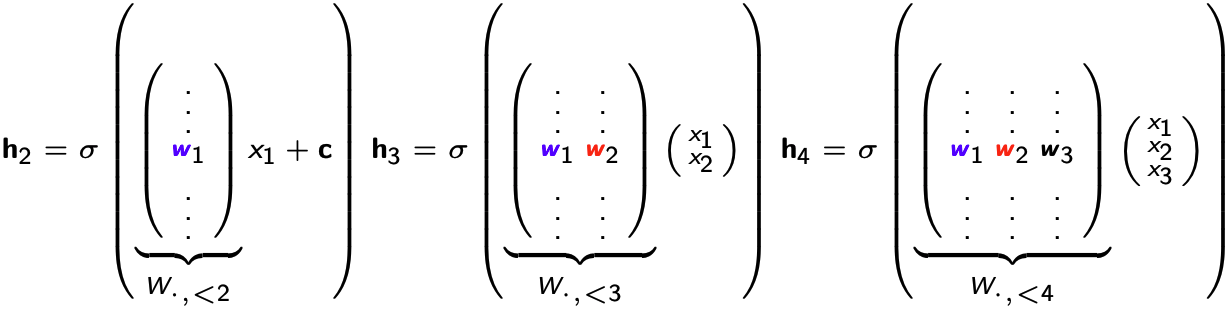
이때 위 수식을 보면 각 hidden layer의 연산 과정에서 $w_1x_1, w_2x_2$ 등이 연속으로 등장하는 것을 볼 수 있다. 따라서 각 데이터에 대한 파라미터를 별개로 저장하는 것이 아니라 공통된 weight $W$에서 필요한 column만을 꺼내서 재사용할 수 있다.
이렇게 weight를 share하는 것은 하나의 이미지를 생성하기 위해 정보를 공유한다는 측면도 있고, 총 파라미터 수를 줄이는 데에도 큰 도움이 된다. FVSBN의 파리마터 수가 데이터 개수에 quadratic한 것에 반해, NADE는 linear하게 증가한다.
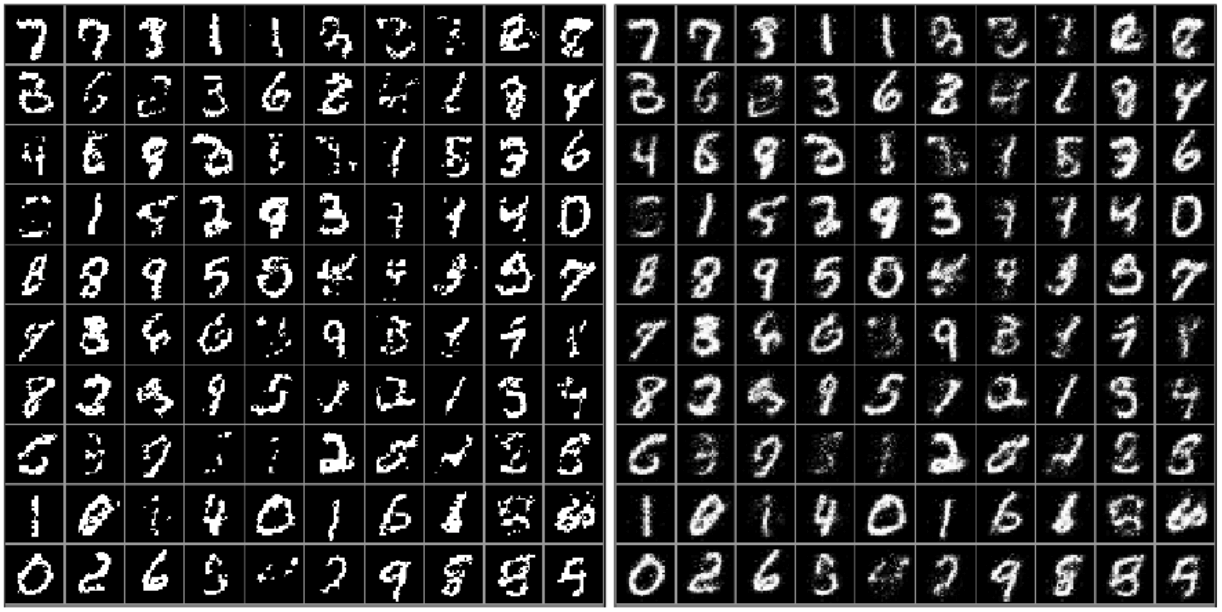
NADE로 생성한 이미지는 위와 같다. 오른쪽 그림이 각 픽셀의 확률값 $\hat{x_i}$를 grayscale로 표현한 것이고, 왼쪽 그림이 이 확률값을 베르누이 분포로 하여 0 또는 1을 샘플링한 것이다.
General Discrete Distributions
0 또는 1의 binarized image가 아닌 0부터 255까지의 grayscale image를 생성하려면 어떻게 해야 할까? 이때는 categorical distribution을 사용한다. 즉, 하나의 픽셀 $x_i$가 가질 수 있는 값이 $K$가지라면, 크기가 $K$인 벡터를 생성하고 각 element마다 확률을 할당하는 것이다. 그러면 그 확률을 이용해서 $x_i$의 값을 샘플링할 수 있다. 수식으로 표현하면 아래와 같다.
$h_i = \sigma(W_{<i}x_{<i} + c)$
$\hat{x}_i = P(X_i = 1 \mid x_1, \cdots, x_{i-1}) = Cat(p_i^1, \cdots, p_i^K) = softmax(A_ih_i + b_i)$
이때 $W_{<i}$와 $x_{<i}$는 $1$부터 $i-1$번째까지의 항목을 모두 행렬 또는 벡터로 만든 것을 뜻한다.
Real-Valued Neural Autoregressive Density Estimation (RNADE)
개념을 더욱 확장해서, 연속적인 값을 갖는 데이터를 생성하는 경우도 생각해 볼 수 있다. 이때는 neural network의 출력이 바로 확률값이 되는 것이 아니라, 우리가 원하는 특정 연속확률분포의 파라미터가 된다. 예를 들어 가우시안 분포라면 평균과 표준편차가 되는 것이다. 이러한 연속확률분포를 원하는 만큼 생성하고 조합할 수 있다.
$p(x_i \mid x_1, \cdots, x_{i-1}) = \sum\limits_{j=1}^{K} \cfrac{1}{K} \mathcal{N}(x_i; \mu_i^j, \sigma_i^{j})$
위의 상황에서는 $i$번째 데이터에 대한 neural network의 출력이 $\{\mu_i^1, \cdots, \mu_i^K\}$와 $\{\sigma_i^1, \cdots, \sigma_i^K\}$가 되는 것이다.
Autoregressive Autoencoders
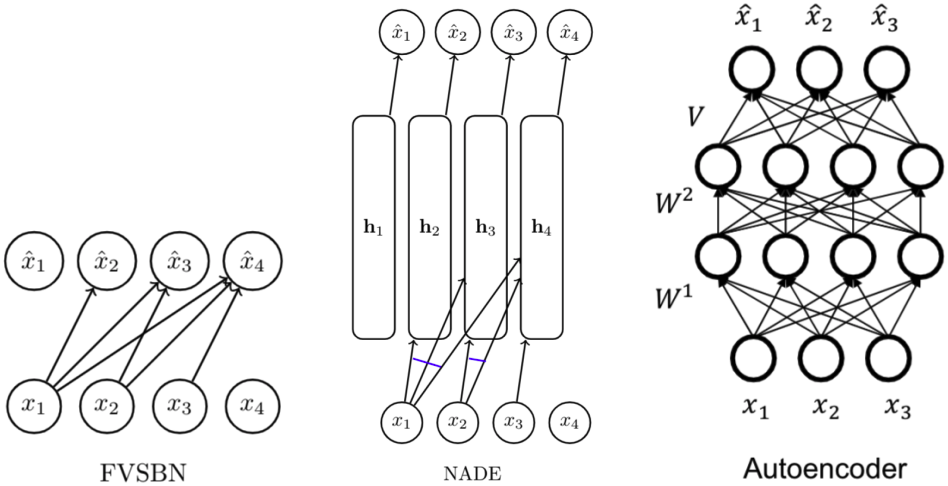
위 다이어그램을 보면 FVSBN, NADE, autoencoder의 아키텍쳐가 형태적으로 유사함을 알 수 있다. 그렇다면 autoencoder를 autoregressive model처럼 사용할 수는 없을까? 하지만 본질적으로 autoencoder는 생성형 모델이 아니며, 데이터의 순서 개념도 없어서 autoregressive model에 꼭 필요한 chain rule을 바로 적용할 수 없다.
우리가 할 수 있는 방법은 autoencoder에 데이터의 순서를 적용하는 것이다. 순서 자체는 사용자가 정하고, autoencoder의 weight을 적당히 mask 처리해서 $i$번째 output은 $1$부터 $i-1$까지의 input에만 영향을 받을 수 있도록 하면 조건부 확률 $P(x_i \mid x_1, \cdots, x_{i-1})$을 모델링할 수 있다.
Autoregressive autoencoders의 한 가지 이점은 training 시에 한 번의 forward pass로 모든 $n$개의 데이터 element에 대한 출력을 얻을 수 있다는 점이다. 다만 inference 시에는 일반 autoregressive 모델처럼 데이터를 출력하고 그 데이터를 다시 입력해서 다음 출력을 얻는 sequential한 방식을 그대로 사용해야 한다.
Recurrent Neural Networks (RNN)
Autoregressive 모델이 가지고 있는 한 가지 한계는 현재 데이터에 대한 출력을 얻기 위해서는 이전 데이터들을 전부 입력해야 한다는 것이다. 이로 인해 데이터의 수가 많아질수록 이전 데이터들이 계속 쌓인다는 문제가 있다. 이를 해결하기 위한 방법으로 RNN이 있다.
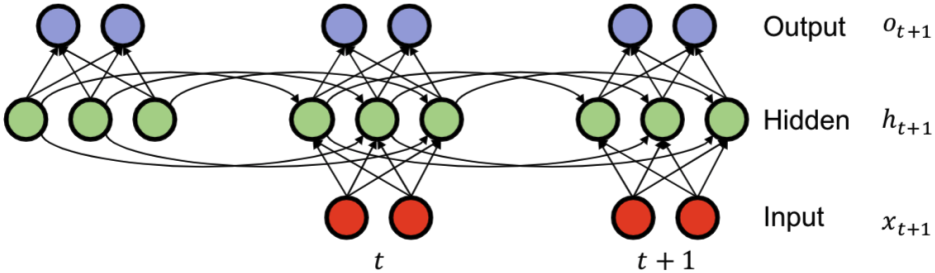
RNN 또한 조건부 확률 $P(x_i \mid x_1, \cdots, x_{i-1})$을 모델링하기 위한 네트워크이다. 다만 RNN은 지금까지 입력받은 데이터를 그대로 갖고 있는 것이 아니라, hidden layer에 summary 형태로 저장한다. 새로운 입력 $x_{t+1}$이 들어오면, hidden layer $h_t$는 아래 수식에 따라 업데이트된다.
$h_{t+1} = \tanh(W_{hh}h_t + W_{xh}x_{t+1})$
Hidden layer $h$를 이용해 출력 $o$을 계산하는 수식은 아래와 같다.
$o_{t+1} = \sigma(W_{hy}h_{t+1})$
수식에서 볼 수 있듯 output이 hidden layer에만 depend하는 것을 알 수 있다.
RNN의 장점으로는 데이터의 길이와 관계없이 사용 가능하며 파라미터 수가 데이터의 길이에 관계없이 고정되어 있다는 것, 그리고 어떤 함수 또는 확률분포든 RNN으로 모델링할 수 있다는 것이 있다. 단점으로는 여전히 데이터의 순서를 정해 주어야 한다는 것과 sequential하게 데이터를 생성해야 하기 때문에 속도가 매우 느리다는 것이 있다. 또한 exploding/vanishing gradient 문제도 있다.
Attention-Based Models
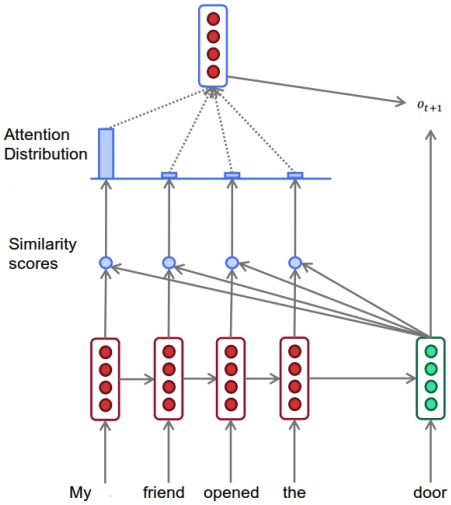
최신 모델들은 attention mechanism을 주로 사용하는데, RNN에서는 하나의 hidden state로 모든 입력을 요약했다면, attention은 NADE와 같이 이전에 입력된 sequence 전체를 사용할 수 있다.
먼저 query vector와 key vector 사이의 similarity score를 구해야 하는데, 두 벡터의 dot product를 통해 구한다. 이 similarity score를 softmax하여 attention weight를 구한다. 이 attention weight를 이용, value vector를 weighted sum하여 위 그림에서의 맨 위 벡터를 얻게 되고, 이 벡터와 현재의 입력을 조합하여 prediction을 하게 된다.
Training 시에는 모든 토큰에 대한 output을 한번에 계산할 수 있는데, autoregressive autoencoders와 비슷하게 masking 처리를 하여 output이 미래의 값에 의존하지 못하게 한다. 다만 이 또한 autoregressive 모델이므로 inference 시에는 recursive하게 출력을 계산해야 한다.
Summary of Autoregressive Models
Autoregressive model은 특정 입력에 대해 그 확률분포 값을 직접 구할 수 있으므로 sampling하기 쉽고 anomaly detection도 자연스럽게 할 수 있다는 장점이 있다. 본문에서 살펴본 베르누이 분포는 직접 확률값을 구했지만, 가우시안 분포 등 더 복잡한 분포에서는 평균과 분산 등 파라미터를 예측하는 방식으로 작동한다. 단점으로는 각 입력에 대한 latent vector를 구하거나 unsupervised learning을 하는 것은 어렵다는 것이 있다.