Data Distribution
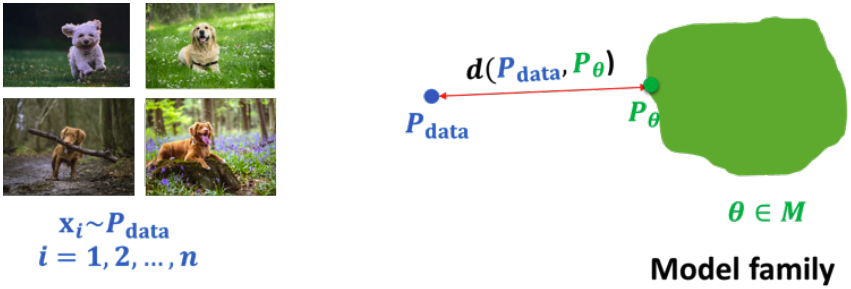
세상에는 다양한 종류의 데이터가 존재한다. Generative AI의 관점에서는, 세상의 모든 데이터는 우리가 모르는 어떤 확률분포 $P_{data}$로부터 샘플링된 것이라고 가정한다. 이 데이터 생성 과정을 잘 모델링해서 $P_{data}$에 근접한 모델을 만들면, 그 모델에서 새로운 데이터를 생성할 수 있다.
이를 위해서는 우선 Model family를 정의해야 한다. Model family란 특정 파라미터들 $\theta$로 정의할 수 있는 확률분포의 집합이다. 예를 들어 model family가 모든 가우시안 분포의 집합이라면 $\theta$는 평균과 표준편차이다. 즉 파라미터 $\theta$만 숫자로 주어지면 확률분포 $P_\theta$가 하나로 결정되는 것이다. 비슷한 예시로 뉴럴 네트워크 또한 모든 파라미터들이 숫자로 결정되면 확률분포 모델이 결정되므로 하나의 NN 아키텍쳐는 하나의 model family가 된다.
우리가 원하는 것은 실제 데이터 분포 $P_{data}$와 가장 근접한 $P_\theta$를 찾는 것이다. 이를 위해서는 두 확률분포 $P_{data}$와 $P_\theta$ 사이의 거리를 정의하는 것도 필요하다. 이때 파라미터의 수가 매우 방대하기 때문에 데이터의 특성을 고려해서 정의하는 것이 중요하다.
Basic Discrete Distributions
위와 같은 세팅에서, 데이터를 $x$라 할 때 우리는 $P_\theta(x)$를 $\theta$와 $x$에 대한 식으로 표현해야 한다. 가장 단순한 세팅에서부터 복잡한 뉴럴 네트워크까지 어떻게 $P_\theta(x)$를 표현할 수 있는지 간단히 알아보자.
Coin Flip
Coin flip은 bernoulli distribution으로 표현할 수 있다. 즉 model family는 $P_p(x) = p^x(1-p)^{1-x}$이다. 이때 필요한 파라미터는 $p$ 하나로, coin이 head가 나올 확률이다. 주어진 전체 trial 중 head가 나온 개수를 세서 가능한 좋은 $p$ 값을 구할 수 있다.
Dice Roll
Biased dice roll은 categorical distribution으로 표현할 수 있다. 즉 주사위의 각 면에 확률이 다르게 할당되어 있는 것이다. 따라서 $P(X = i) = p_i$로 표현할 수 있고, 각 면에 대한 확률 $p_i$가 우리가 찾아야 할 파라미터가 된다. 이때 모든 면의 확률을 더하면 1이 되어야 한다는 조건이 있다.
Pixel Color
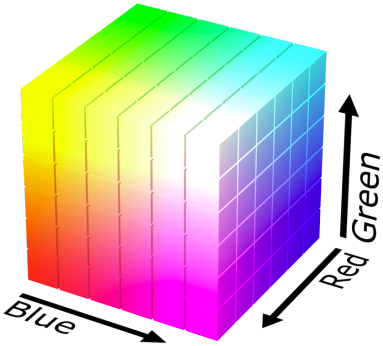
하나의 RGB 픽셀의 색을 모델링할 때를 생각해 보자. 각 RGB 채널은 0부터 255까지의 값을 가질 수 있으므로 Categorical distribution을 각 채널마다 적용할 수 있다. 먼저 $P(R = r) = p_r$을 모든 $r = 0, 1, \cdots, 255$에 대해 숫자로 정해야 한다. 마찬가지로 $P(G = g) = p_g$와 $P(B = b) = p_b$도 정의할 수 있다. 따라서 모든 채널의 값이 한번에 정해지려면 joint distribution $P(R = r, G = g, B = b)$를 구해야 한다. 이때 모든 경우의 수에 대해 파라미터를 하나씩 할당하면 총 파라미터의 수는 $256^3 - 1$로 매우 커지게 된다.
2D Binary Image

이제 2D binary image를 모델링해 보자. 앞의 예시와 비슷하게 joint distribution을 구하기 위해서는 모든 가능한 경우의 수에 대해 파라미터를 할당해야 한다. 이때 총 픽셀의 수를 $n$이라 하면, 가능한 모든 이미지의 조합은 $2^n$개가 된다. 각 경우의 수에 대해 확률 $P(x_1, x_2, \cdots, x_n)$을 할당하면 총 파라미터의 수는 $2^n - 1$이 된다.
MNIST와 같은 데이터셋을 이용해 이러한 모델을 어떤 방식으로든 학습할 수 있다면, 우리는 가능한 모든 이미지에 대해 확률을 할당하는 것이 되고, 이 확률분포에서 새로운 이미지를 생성할 수 있다. 또한 데이터셋에 없는 새로운 이미지가 들어왔을 때 그 input이 실제로 valid한 이미지인지 이미 할당된 확률을 통해 판단할 수도 있다.
Bayes Network
위와 같이 모든 경우의 수에 대해 확률을 할당하는 방식은 파라미터의 수가 너무 커져서 실제로 학습하거나 메모리에 저장하는 것이 불가능하다. 이를 해결하기 위해 joint distribution에 chain rule을 적용해 아래와 같이 조건부 확률으로 쪼갤 수 있다.
$P(x_1, x_2, \cdots, x_n) = P(x_1)P(x_2 \mid x_1)P(x_3 \mid x_1, x_2)\cdots P(x_n \mid x_1, x_2, \cdots, x_{n-1})$
Chain rule 그 자체로는 파라미터의 수를 줄이지 못한다. 위의 예시에서 $P(x_1)$은 파라미터가 1개 필요하지만 $P(x_2 \mid x_1)$은 $x_1 = 0$일 때와 $x_1 = 1$일 때 각각에 대해 확률을 저장해야 하므로 파라미터가 2개 필요하다. 즉, 총 파라미터의 수는 여전히 $1 + 2 + 2^2 + \cdots + 2^{n-1} = 2^n - 1$이 된다.
하지만 이 조건부 확률을 변형해서 conditional independence 가정을 적용할 수 있다. 즉, 각각의 변수 $x_i$가 순차적으로 이전 변수들에 dependent하는 것이 아니라 특정 몇몇 변수들에만 dependent하다는 가정이다. 이 변수들을 parents라 하는데, $x_{A_i}$라고 표시하면 joint distribution은 아래와 같이 표현할 수 있다.
$P(x_1, x_2, \cdots, x_n) = \prod\limits_{i=1}^n P(x_i \mid x_{A_i})$
이때의 파라미터 수는 parents set의 크기에 비례하게 되므로 총 파라미터의 수를 크게 줄일 수 있다. 이러한 형태의 joint distribution을 Bayes Network라고 한다. 이때 각 변수들이 어떤 변수들에 dependent한지를 Directed Acyclic Graph (DAG)로 나타낼 수 있다.
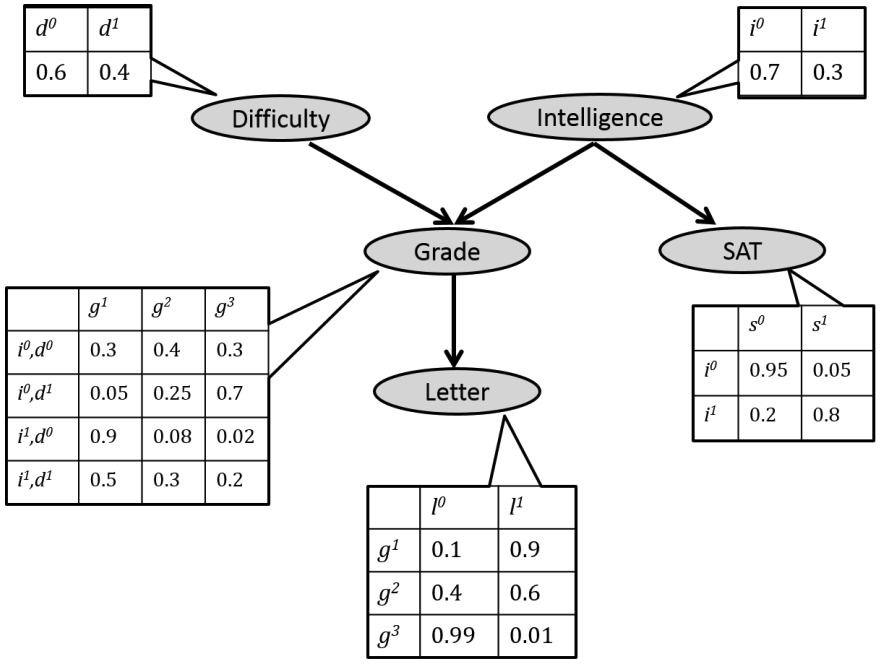
Bayesian Network의 예시로 위의 그래프를 살펴보자. Difficulty와 Intelligence는 독립된 변수들이고, Grade는 Difficulty와 Intelligence에, SAT는 Intelligence에 의존한다. Letter는 Grade에 의존한다. 이러한 경우 전체 joint distribution은 아래와 같이 쓸 수 있다.
$P(D, I, G, S, L) = P(D)P(I)P(G \mid D, I)P(S \mid I)P(L \mid G)$
즉, 서로 연관이 있는 변수들 사이의 조건부 확률만을 위 그림과 같이 표와 같은 방식으로 저장하면 되기 때문에, 모든 경우의 수를 5차원 공간에 저장해야 하는 최초의 접근법보다 훨씬 효율적이다.
$D \perp I, \quad S \perp \{D, G\} \mid I, \quad L \perp \{D, I, S\} \mid G$
이때의 conditional independence를 위와 같이 표현할 수 있다. 즉, "$I$가 주어졌을 때" $S$는 $D$와 $G$에 대해 독립이고 "$G$가 주어졌을 때" $L$은 $D$, $I$, $S$에 대해 독립이다.
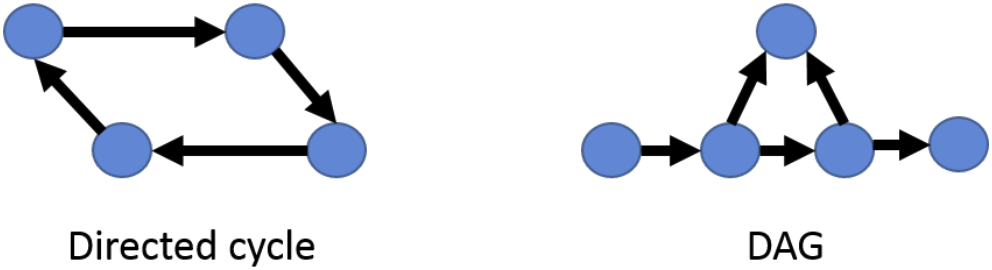
Bayesian Network에서는 변수들 간 dependency에는 loop가 없어야 한다. 위의 왼쪽 그래프와 같이 loop가 있는 경우는 joint distribution을 식으로 표현할 수 없다. 따라서 위의 오른쪽 그림과 같이 시작과 끝이 있는 "Acyclic" 구조여야 한다.
Extension to Continuous Variables
지금까지는 이산적인 변수들에 대해 다뤘지만, 연속 변수인 경우에도 위의 모든 방식을 적용할 수 있다. 예를 들어 가우시안 분포는
$P(x) = \cfrac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\cfrac{(x - \mu)^2}{2\sigma^2}\right)$
의 분포를 따르게 되는데, $\mu$와 $\sigma$를 통해 $P(x)$를 구할 수 있다. 연속확률분포의 경우에도 chain rule, conditional independence, Bayesian Network 등을 이용해 joint distribution을 표현할 수 있다.
Discriminative Tasks
분류 문제를 풀 수 있는 다양한 방법을 알아보고 확률분포의 관점에서 discriminative model과 generative model의 차이점을 살펴보자.
Naive Bayes
Naive Bayes는 Bayesian Network의 특별한 경우로, 모든 변수들이 하나의 변수에만 dependent하다는 가정을 한다. 어떤 이메일을 스팸인지 $(Y = 1)$ 아닌지 $(Y = 0)$ 예측하는 classification 문제를 예로 들어 보자. 이때 이메일의 단어는 $x_1, x_2, \cdots, x_n$으로 $n$개이다. 따라서 joint distribution은 $P(Y, x_1, x_2, \cdots, x_n)$가 되고, 이메일들이 이러한 unknown true distribution으로부터 생성되는 것이라고 생각할 수 있다.
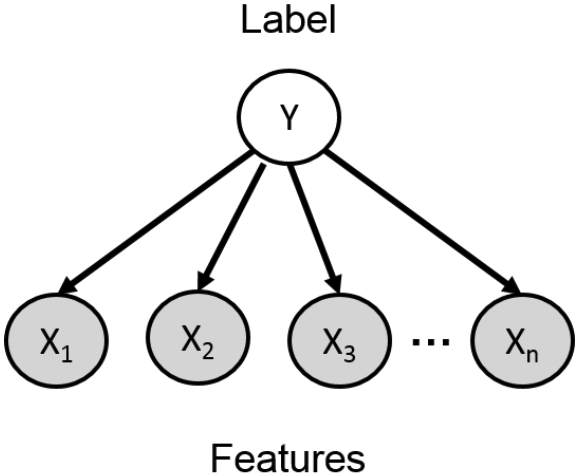
이때 Bayesian Network를 위의 그림과 같이 표현한다면, $Y$가 주어졌을 때 이메일의 단어들은 각각 독립적인 것이 되고 joint distribution은 아래와 같이 표현할 수 있다.
$P(Y, x_1, x_2, \cdots, x_n) = P(Y)P(x_1 \mid Y)P(x_2 \mid Y)\cdots P(x_n \mid Y)$
$P(x_i \mid Y)$는 training dataset으로부터 셀 수 있으므로 Bayes' rule을 이용해 데이터로부터 label을 예측할 수 있다.
$P(Y = 1 \mid x_1, x_2, \cdots, x_n) = \cfrac{P(Y = 1)\prod\limits_{i=1}^n P(x_i \mid Y = 1)}{\sum\limits_{y \in \{0, 1\}} P(Y = y)\prod\limits_{i=1}^n P(x_i \mid Y = y)}$
위 그림을 살펴보면 화살표의 방향이 $Y$에서 $x_i$로 향하고 있으므로 $Y$가 주어졌을 때 $x_i$의 분포를 결정하는 생성형 모델이다. 이 생성형 모델을 classification에 이용하기 위해서는 위 수식에서처럼 $P(Y)$를 알아야 하고 $P(X \mid Y)$를 표현할 수 있어야 한다는 어려움이 있다.
반대로 화살표가 $x_i$에서 $Y$로 향하는 discriminative model을 생각해 보면, $P(Y \mid X)$를 바로 표현하면 되므로 수식이 훨씬 간단해진다. 이때 단어 $x_i$ 사이의 연관관계는 고려되지 않는데, 그 이유는 우리가 원하는 것이 이메일의 생성 과정을 모델링하는 것이 아니라 조건부 확률 $P(Y \mid X)$뿐이기 때문이다. 즉, 모델의 입력으로 항상 데이터 $X$가 주어지기 때문에 데이터 자체의 분포 $P(X)$는 모델링할 필요가 없다.
Logistic Regression
Discriminative model에서 $P(Y \mid X)$를 조금 더 간단히 표현할 수 있는 방법은 logistic regression을 이용하는 것이다. 기존에는 $P(Y, x_1, x_2, \cdots, x_n)$를 표로 나타내고 각각의 경우의 수를 하나의 파라미터로 표현했는데, 이를 특정 함수의 형태로 나타내는 것이다.
$P(Y = 1 \mid X; \alpha) = f(X, \alpha)$
이렇게 표현함으로써 확률분포가 특정 함수의 형태로 고정되어 유연성이 떨어진다는 단점이 있지만 파라미터의 수가 크게 줄어든다. Logistic regression의 경우 $X$의 크기가 $n$이라면 weight $n$개와 bias 1개로 총 $n+1$개의 파라미터만 있으면 된다.
$f(X, \alpha) = \text{sigmoid}(\alpha_0 + \sum\limits_{i=1}^n \alpha_i x_i)$
이때 $Y$와 $x_i$ 사이에는 linear한 관계가 있다고 가정하고, 이를 sigmoid 함수를 통해 0과 1 사이의 값으로 변환한다. 이를 Linear dependence라고 한다. Naive Bayes에서 사용했던 conditional independence와는 다른데, Naive Bayes에서는 $Y$가 주어졌을 때 $x_i$끼리 서로 독립이라는 명시적인 가정을 했지만 Logistic regression에서는 $x_i$끼리 수식적으로는 연관성이 없지만 실제로 데이터에는 연관성이 있을 수 있다.
예를 들어 "bank"와 "account"처럼 같이 쓰이는 단어들의 경우, Naive Bayes에서는 이 두 단어가 서로 독립이라고 가정하기 때문에 둘의 결과에 대한 영향이 별개로 취급되지만, Logistic regression에서는 이 둘의 결과에 대한 영향이 서로 연관되어 있다고 보고 둘 중 하나에 해당하는 $\alpha_i$의 값을 줄여 두 단어를 하나로 취급하는 효과를 낼 수 있다. 이처럼 assumption이 약하기 때문에 실제 데이터에 대해 logistic regression이 더 잘 동작한다.
하지만 여전히 discriminative model이기 때문에, $P(Y \mid X)$만을 표현할 뿐 $P(X)$는 모델링하지 않는다. 즉 이메일을 분류할 수만 있지 새로운 이메일을 생성할 수는 없다.
Discriminative Neural Models
Neural network 또한 Logistic regression와 같이 확률분포 $P(Y \mid X)$를 함수로 표현하는 모델이다.
$P(Y = 1 \mid X; \alpha) = f(X, \alpha)$
이때 차이점은 함수 $f$의 복잡도이다. Logistic regression의 경우 $X$와 $Y$ 사이에 선형적인 관계를 가정한다. Neural Network의 경우 이러한 assumtion을 더욱 약하게 하기 위해 hidden layer와 nonlinear function을 추가한다.
$f(X, \alpha) = \text{sigmoid}(W_2 \cdot g(W_1 X + b_1) + b_2)$
위 수식에서 $g$가 nonlinear function이다. 이를 통해 $X$와 $Y$ 사이의 연관성을 더욱 유연하게 표현할 수 있다. 이러한 layer들을 깊게 쌓음으로써 더욱 복잡한 관계를 표현할 수 있다.
Building Generative Models
조건부 확률분포를 모델링하는 discriminative models를 이용해서 전체 joint distribution을 모델링하는 생성형 모델을 만들 수 있다.
$P(x_1, x_2, x_3, x_4) = P(x_1)P(x_2 \mid x_1)P_\text{neural}(x_3 \mid x_1, x_2)P_\text{neural}(x_4 \mid x_1, x_2, x_3)$
예를 들어 Autoregressive models의 경우 위 수식과 같이 복잡한 확률분포에 해당하는 부분들을 뉴럴 네트워크로 대체한다.
Bayesian Network나 Neural Network를 함께 이용해 joint distribution을 모델링할 수 있다. 예를 들어 Bayesian Network가 $Z \rightarrow X$이라면 아래와 같이 표현할 수 있다.
$P(X, Z) = P(Z)P(X \mid Z)$
$Z$가 Bernoulli distribution을 따른다면, $X$는 $Z$ 값에 따라 다른 파라미터를 가지는 형태로 모델링할 수 있다.
다른 예시로 Variational Autoencoder가 있는데, 위와 동일한 $Z \rightarrow X$ 형태의 Bayesian Network에서 $Z$와 $X$가 모두 Gaussian distribution이다. 이때 $Z$는 $N(0, 1)$을 따르고, $X$의 평균과 표준편차는 $Z$를 입력으로 받는 Neural Network의 출력으로 나타낸다. 이러한 방식으로 Bayesian Network와 Neural Network를 함께 사용할 수도 있다. 이러한 방식으로 Bayesian Network와 Neural Network를 함께 사용할 수도 있다.